使用 ChatGPT 协助 MUSA 代码生成和运行
2024-11-30
1 引言
随着人工智能技术的蓬勃发展,智能对话系统如ChatGPT在许多领域中发挥着重要作用。这些系统�不仅限于对话生成和问题回答,还可以用于编写代码和帮助软件开发。尤其是在生成特定领域语言代码方面,ChatGPT展现出了极大的潜力。本文将探讨如何使用ChatGPT生成MUSA代码,以及这项技术如何促进程序设计和开发过程的简化。MUSA是摩尔线程设计推出的统一系统架构,兼容CUDA,依托摩尔线程GPU,使用户更简单高效发挥出GPU的算力。
值得注意的是,使用ChatGPT时需要注意商业秘密的保护,不要上传公司机密或核心代码,否则有被泄露的风险。
2 使用ChatGPT生成MUSA代码
2.1 生成CUDA代码
CUDA作为目前广泛使用的GPU编程语言,ChatGPT学习了大量CUDA相关的知识,使得我们可以通过对话快速的生成CUDA代码,并且可以顺利运行。 我们以矩阵乘法为例,使用ChatGPT生成一个CUDA代码:
Q:请使用CUDA生成矩阵乘法代码
A:下面是一个 CUDA 实现的矩阵乘法示例代码:
#include <stdio.h>
#include <stdlib.h>
// 定义矩阵的维度
#define N 16 // 可以根据需要调整矩阵大小
// CUDA kernel 函数,用于矩阵乘法
__global__ void matrixMultiply(float *A, float *B, float *C, int n) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < n) {
float sum = 0.0;
for (int k = 0; k < n; k++) {
sum += A[row * n + k] * B[k * n + col];
}
C[row * n + col] = sum;
}
}
// 主函数
int main() {
int size = N * N * sizeof(float);
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
// 初始化矩阵 A 和 B
for (int i = 0; i < N * N; i++) {
h_A[i] = 1.0f; // 可以根据需要修改初始化值
h_B[i] = 1.0f;
}
float *d_A, *d_B, *d_C;
cudaMalloc((void **)&d_A, size);
cudaMalloc((void **)&d_B, size);
cudaMalloc((void **)&d_C, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
dim3 blockSize(16, 16);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x, (N + blockSize.y - 1) / blockSize.y);
// 调用 CUDA kernel
matrixMultiply<<<gridSize, blockSize>>>(d_A, d_B, d_C, N);
// 等待 GPU 计算完成
cudaDeviceSynchronize();
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 打印结果矩阵 C
printf("Result matrix C:\n");
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
printf("%f ", h_C[i * N + j]);
}
printf("\n");
}
// 释放内存
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}
我们可以看到上述代码是一段非常完整并且可以正确运行的CUDA代码
我们在Intel CPU + Nvidia 3070显卡的环境一下编译并运行这一段代码,可以看到屏幕上正确的输出了结果矩阵C的内容:
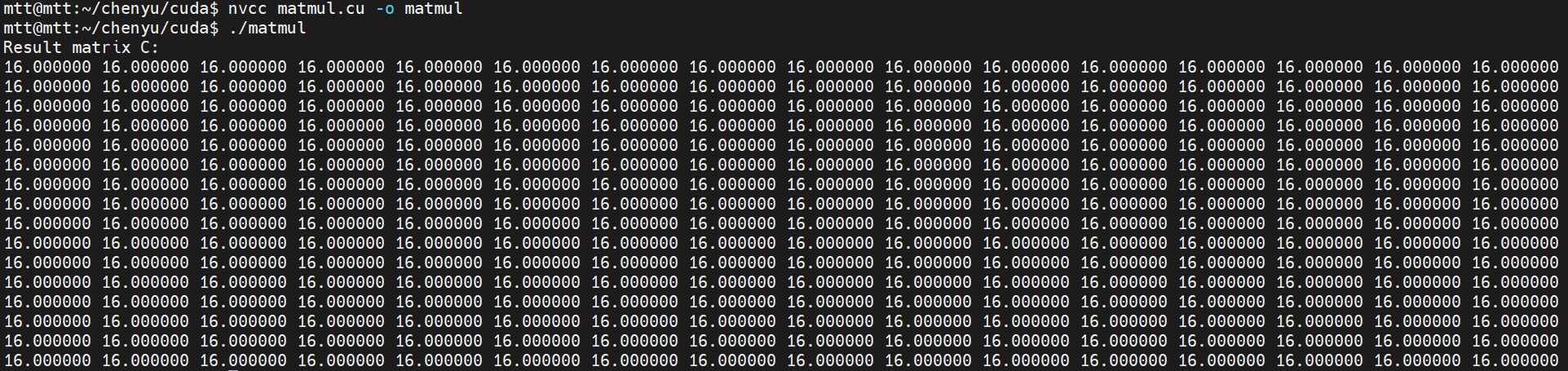
2.2 通过CUDA代码生成MUSA代码
因为MUSA语法与CUDA语法的相似性,我们可以让ChatGPT直接将这个代码修改为MUSA代码
Q:将这段代码改成MUSA代码
A:将 CUDA 代码改为 MUSA(摩尔线程的 GPU 计算平台)代码时,基本语法和 CUDA 非常相似,只需替换掉 CUDA 特有的前缀和调用。以下是上述矩阵乘法代码的 MUSA 版本:
#include <stdio.h>
#include <stdlib.h>
#include <musa_runtime.h> // 包含 MUSA 的头文件
// 定义矩阵的维度
#define N 16 // 可以根据需要调整矩阵大小
// MUSA kernel 函数,用于矩阵乘法
__global__ void matrixMultiply(float *A, float *B, float *C, int n) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < n) {
float sum = 0.0;
for (int k = 0; k < n; k++) {
sum += A[row * n + k] * B[k * n + col];
}
C[row * n + col] = sum;
}
}
// 主函数
int main() {
int size = N * N * sizeof(float);
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
// 初始化矩阵 A 和 B
for (int i = 0; i < N * N; i++) {
h_A[i] = 1.0f; // 可以根据需要修改初始化值
h_B[i] = 1.0f;
}
float *d_A, *d_B, *d_C;
musaMalloc((void **)&d_A, size);
musaMalloc((void **)&d_B, size);
musaMalloc((void **)&d_C, size);
musaMemcpy(d_A, h_A, size, musaMemcpyHostToDevice);
musaMemcpy(d_B, h_B, size, musaMemcpyHostToDevice);
dim3 blockSize(16, 16);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x, (N + blockSize.y - 1) / blockSize.y);
// 调用 MUSA kernel
matrixMultiply<<<gridSize, blockSize>>>(d_A, d_B, d_C, N);
// 等待 GPU 计算完成
musaDeviceSynchronize();
musaMemcpy(h_C, d_C, size, musaMemcpyDeviceToHost);
// 打印结果矩阵 C
printf("Result matrix C:\n");
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
printf("%f ", h_C[i * N + j]);
}
printf("\n");
}
// 释放内存
free(h_A);
free(h_B);
free(h_C);
musaFree(d_A);
musaFree(d_B);
musaFree(d_C);
return 0;
}
我们可以看到,上述代码当中,原有的CUDA API已经被��准确的替换成了MUSA API,例如cudaMalloc → musaMalloc, cudaMemcpy → musaMemcpy等等。修改后的代码可以直接运行在MUSA GPU设备上,并输出正确的内容。
我们在Intel CPU + MTT S80的环境上进行编译并运行,可以看到编译正常屏幕上正确的输出了结果矩阵C的内容:
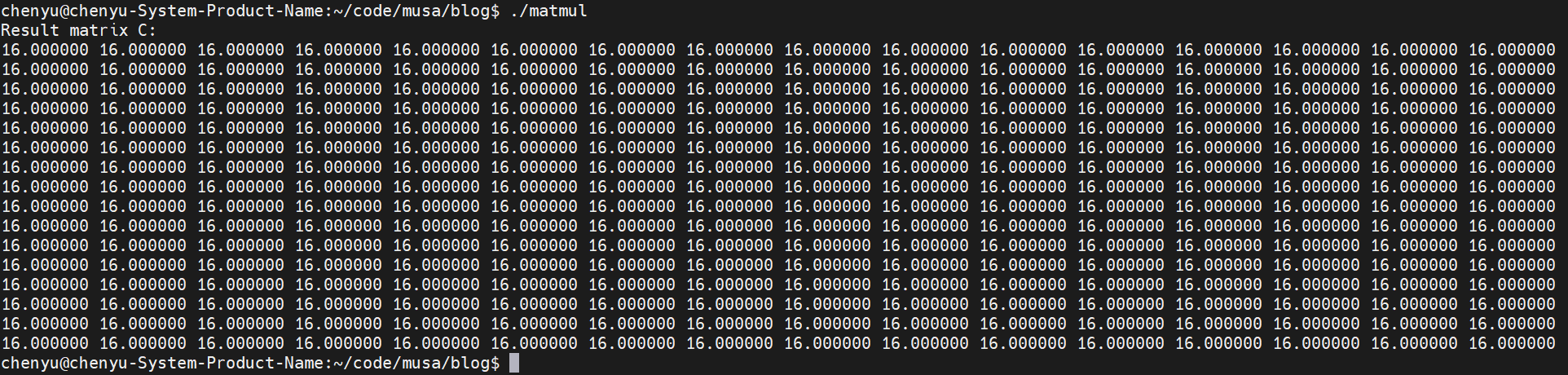
2.3 直接生成MUSA代码
随着MUSA代码的广泛应用,我们不仅可以通过CUDA代码转换MUSA代码,也可以让ChatGPT直接生成MUSA代码
Q:请使用摩尔线程的MUSA生成向量加法代码
A:以下是使用摩尔线程的 MUSA 架构进行向量加法的示例代码:
#include <iostream>
#include <musa_runtime_api.h> // MUSA API 头文件
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
C[i] = A[i] + B[i];
}
}
int main() {
const int N = 1024; // 向量大小
const int size = N * sizeof(float);
// 在主机上分配内存
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// 初始化输入数据
for (int i = 0; i < N; i++) {
h_A[i] = static_cast<float>(i);
h_B[i] = static_cast<float>(N - i);
}
// 在 MUSA 设备上分配内存
float *d_A, *d_B, *d_C;
musaMalloc(&d_A, size);
musaMalloc(&d_B, size);
musaMalloc(&d_C, size);
// 将数据从主机复制到设备
musaMemcpy(d_A, h_A, size, musaMemcpyHostToDevice);
musaMemcpy(d_B, h_B, size, musaMemcpyHostToDevice);
// 启动核函数,假设每个线程块128个线程
int threadsPerBlock = 128;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 将结果从设备复制回主机
musaMemcpy(h_C, d_C, size, musaMemcpyDeviceToHost);
// 打印结果的一部分进行验证
for (int i = 0; i < 10; i++) {
std::cout << "C[" << i << "] = " << h_C[i] << std::endl;
}
// 释放内存
musaFree(d_A);
musaFree(d_B);
musaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
我们可以看到ChatGPT也准确的生成了MUSA代码,并且使用musa_runtime_api.h替换了musa_runtime.h。
我们在Intel CPU + MTT S80的环境上进行编译并运行,可以看到编译结果无报错,并且可以正确的输出一部分结果:

3 展望
随着人工智能技术的不断进步,使用ChatGPT生成MUSA代码将变得更加高效和便捷。开发者可以通过自然语言输入描述所需功能,ChatGPT将迅速解析需求并自动生��成高性能的MUSA代码,减少传统编程过程中的时间和精力消耗。这样的系统不仅可以提升开发效率,还能降低因手动编写代码而可能出现的错误。此外,随着对深度学习和并行计算需求的增加,ChatGPT在这一领域的应用潜力将日益显现,为更多用户提供可定制化的解决方案,从而推动高性能计算的发展。

