MTT S4000 张量核心 GEMM 优化的推导、编译器调优与异步边界探索
1. GEMM背景
矩阵乘法是深度学习中最常用且最耗时的算法之一。在神经网络的训练和推理中,矩阵乘法作为基础的算子会被高频次反复调用。因此,在GPU上实现高效的矩阵乘法对于深度学习任务的性能至关重要。
一般而言,在GPU上实现矩阵乘法主要有两种途径。一是使用通用计算单元完成矩阵乘法运算,二是使用专用的张量计算核心完成矩阵乘法运算。具体而言,在英伟达最早推出张量计算核心之前,矩阵乘法通常是在通用计算单元上完成的,此种实现方法不依赖芯片上额外的张量核心,但是计算效率较为一般。而在张量核心问世之后,我们会更倾向将大规模矩阵乘法运算放在更高效的张量计算核心上完成。因此在本文中,我们将使用MUSA SDK中的WMMA库调用张量计算核心完成8192×8192×16384超大规模的矩阵乘法运算。
2. 摩尔线程s4000显卡硬件架构解读
截至目前(2026/3/16),摩尔线程显卡目前一共有4款架构,分别是MP_10、MP_21、MP_22、MP_31,本次使用的s4000属于其中的MP_22架构。
如图1所示,S4000一共拥有8个MUSA处理器簇(MUSA Processor Cluster,MPC),每个MPC包含4个MUSA 处理器执行引擎(MUSA Processor eXecution engine, MPX),每个MPX包含2个MUSA处理器(MUSA Processor, MP),即S4000一共拥有8×4×2=64个MP。值得注意的是,S4000拥有1MB大小由2个MPX即4个MP所共享的L2缓存和全局共享24MB大小的L3缓存。
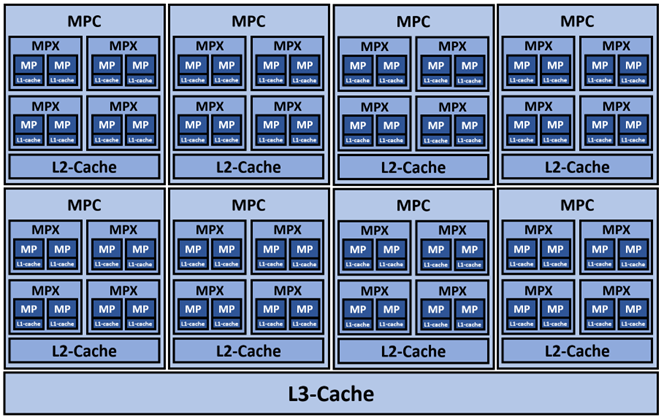
图1. S4000内核架构图
目前,摩尔线程所有GPU的 warp size 均为128,即一个线程束中存在128个线程,是传统英伟达显卡的4倍,具有更宽的执行宽度。
S4000的 local memory 拥有32个 bank,一次内存事务产生的读写的数据量最大是32 float即64 half。因此在读写local memory时,我们需要保证一个warp中不同的thread的地址要命中在连续且不同的32个bank中,从而获得最大的读写速度。
此外,S4000每一个MP单元拥有131072个32 bit 寄存器,73728 byte 本地内存,允许最多被分配6144个 thread 即6144/128=48个warp。每一个block最多允许使用1024个thread,而每一个thread最多拥有256个寄存器。
注意,只有一个block为512个thread的时候,每个thread才能拥有256个寄存器,如果有1024个thread,那么每个thread只能拥有128个寄存器。
最后,通过查阅MUSA SDK的 wmma 库,我们得知,MP_22 架构的张量核心在 FP16 数值精度上主要支持16×8×8、16×16×8、16×16×16和32×32×16这四种尺寸的MMA。
至此,我们获得了我们优化HGEMM算子所需的全部硬件规格,留意上述硬件指标对于后续的优化很重要。
3. S4000上HGEMM算子具体优化实践
先简单捋一下整体代码的思路,看看每个block都需要做什么。
- 先声明寄存器(Frag A、B、C)和本地内存(Local memory A、B、C),并将Frag C置零。
- 读取全局内存(Global memory A、B),存入本地内存(Local memory A、B)。
- 读取本地内存(Local memory A、B),存入寄存器(Frag A、B)。
- 调用 wmma 库,完成 mma 累加计算,结果落回 Frag C(使用单精度做累加保证计算精度,因此这里的Frag C的数值类型是单精度)。
- 循环重复Step2、3、4。
- 将 Frag C 落回本地内存 Local memory C。
- 将 Local memory C 的数值类型转换为半精度,落回全局内存。
完成上述基础的代码编写,我们可以获得大约10TFLOPS的基线计算性能。GEMM一般被认为是 compute bound 的任务。也就是说,经过良好设计后的程序是可以完全吃满计算核心而不受显存带宽的影响。而为了实现此目标,我们往往会从以下8个角度开展HGEMM算子的优化。
3.1 Block分块和warp分块
这是最基础也是最重要的性能优化,分块的好坏对性能的影响立竿见影,并且直接关系到最终算子的性能上限。
在此项优化中,我们需要确认每个 block 和 warp 需要完成多大规模的矩阵乘法运算,以及每个 MP 单元分配多少个 block。具体而言,每个 block 完成的矩阵乘法运算的规模越�大,在本地内存中共享的数据就会越多,从而能够提高计算访存比;每个 warp 需要完成的矩阵乘法运算规模越小,block 内 warp 数越多,则能够提高运算并行度;每个 MP 单元能够分配更多的 block,则有更多的满足发射的 warp 可供调度,掩盖读写延迟。
因此,这过程可谓是戴着镣铐跳舞。既要需要寻求一个尺寸上的良好平衡,又需要检查程序是否满足各项约束条件。例如寄存器、本地内存的用量不能超过MP硬件支持的上限,单个 Block 不能使用超过1024个 thread 等等。
最直接的方法是列个大表格,把所有可能的情况全部列举出来做分析。一个简化示意版如表1所示。该表固定了 MMA 子块大小为16×16×16,MMA per warp为8即每个 warp 做8次 MMA 计算,通过修改每个 MP 上贮存的 block 数量分析寄存器和本地内存的消耗数量。
表1. 每个warp做8次16×16×16 MMA的情况下可行性分析
| MMA_M | MMA_N | MMA_K | MMA per warp | Block per MP | Thread per block | Warp per block | Reg per block | Local mem per block | 可行性? |
|---|---|---|---|---|---|---|---|---|---|
| 16 | 16 | 16 | 8 | 1 | 1024 | 8 | 22528 | 8192 | TRUE |
| 16 | 16 | 16 | 8 | 2 | 1024 | 8 | 22528 | 8192 | TRUE |
| 16 | 16 | 16 | 8 | 3 | 1024 | 8 | 22528 | 8192 | TRUE |
| 16 | 16 | 16 | 8 | 4 | 1024 | 8 | 22528 | 8192 | TRUE |
| 16 | 16 | 16 | 8 | 5 | 1024 | 8 | 22528 | 8192 | FALSE |
| 16 | 16 | 16 | 8 | 6 | 1024 | 8 | 22528 | 8192 | FALSE |
| 16 | 16 | 16 | 8 | 12 | 512 | 4 | 14336 | 6144 | FALSE |
| 16 | 16 | 16 | 8 | 24 | 256 | 2 | 10240 | 4096 | FALSE |
| 16 | 16 | 16 | 8 | 48 | 128 | 1 | 8192 | 3072 | FALSE |
首先,每个block上的thread数量不能超过1024,每个MP上的thread数量不能超过6144,根据这两个约束条件我们可以得到每个block在每种情况下应该分配多少个thread。
例如在每个MP分配6个block的情况下,我们还可以为每个block分配1024个thread,但是在为每个MP分配12个block的情况下,我们只能为每个block分配512个thread,否则会超出每个MP最多6144(=12×512)个thread的约束上限。
在确定输入参数后,便可以根据程序的初步设计完成寄存器和本地内存需求数计算。HGEMM中主要需要用到Frag A、B、C三块寄存器。其中无论数值精度是FP16还是FP32,每个数字都需要占用一个完整寄存器。以表1第4行标蓝的情况举例,如图2所示,一个warp内做8次16×16×16大小的MMA计算,那么每一个warp就需要处理(16×4)×(16×2)大小的矩阵。对于Frag C来说就需要64×32=2048大小的寄存器来承接结果。
Frag A和B的情况则有些许不同。从理想情况上来说,我们希望数据只从本地内存中取一次,并且使得存放在寄存器中的数据最少。而最符合理想情况的做法是:
- 首先取B1、A1,计算C1_1;
- 接着取B2,计算C1_2;
- 再释放A1,取A2,计算B2_1和B2_2;
- 然后是释放A2,取A3,计算A3_1和A3_2
以此类推。因此对于Frag A来说需要16×16/2=128大小的寄存器,对于Frag B来说需要16×16×2/2=256大小的寄存器。
最后经过计算得知每个block中的8个warp一共需要(2048+256+512)×8=22528个寄存器用于Frag A、B和C存储矩阵数值。此外,程序运行过程中还需要一些寄存器存储地址、中间变量等信息,寄存器的额外使用量会受到编译器影响,这部分寄存器数量我们无法做精确计算,但可以做简单粗略地估计。每个MP单元拥有131072个寄存器,131072/22528≈5.8,所以在寄存器约束下考虑,放下5个block是没问题的。
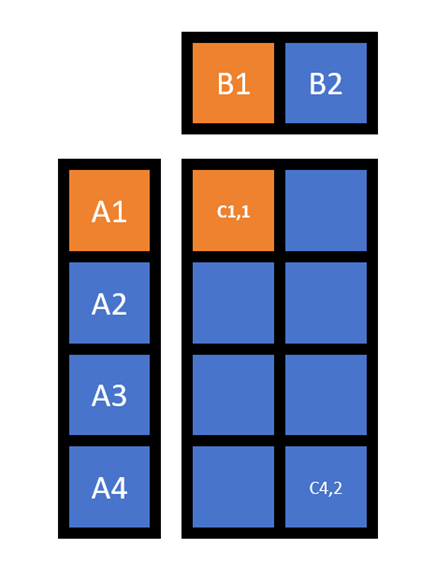
图2. Warp内8次MMA计算示意图
本地内存占用计算也是类似的。HGEMM中一共用到了3块本地内存,分别是local memory A、B、C。
我们首先注意到一点,local memory A、B和local memory C可以分时复用,即本地内存同一时刻只会存在local memory A、B或者local memory C,不会同时占用本地内存。所以本地内存的用量将会是max( A+B,C)。在编写程序的时候我们可以使用联合体union告知编译器来保证这点,写作:
__shared__ union {
struct {half a[?]; half b[?];} ab;
float c[?];
} local_memory;
接着,我们分析local memory C所需的内存空间。由于目前还不支持在寄存器中直接把Frag C数值精度转换为 half ,因此local memory C的数值精度需要保留在 float。但是如果完整保存整个计算结果所需的空间过大。如图3所示,一个block�完成的计算尺寸为128×128=16384,也就是说local memory C需要存储16384个float,这样的大小显然是不可接受的。实际上,我们并不需要一次性把所有结果全部写到local memory中,而是只暂存一部分(图3中的橙色部分),写回全局内存之后再从寄存器中存下一部分,这样在不损失性能的情况下只需要原来1/8的存储空间即16384/8=2048个float。
Local memory A、B的情况也是类似的,在不考虑双、多缓冲的情况下,A和B每次各自需要存储16×128=2048个 half。而表格中的计算结果是在考虑了一次性取4次的情况。
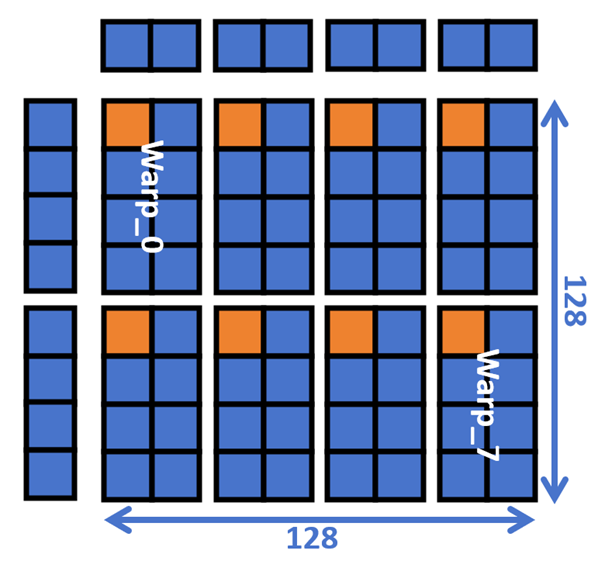
图3. Block中8个warp分布示意图
除了寄存器和本地内存用量约束估计,我们还能计算出寄存器/本地内存浪费数、计算访存比等能辅助我们选择的参数。
值得注意的是,上述计算中存在一些人为的设定,例如双缓冲或是多缓冲、padding之类的不同策略以及对缓存大小的各种考量都会影响最终的计算结果,还需做更多的实验才能够较好地确定参数组合。类似的,我们还可以绘制出其他情况比如每个warp做4次32×32×16 MMA的表格,如表2所示,此处不再过多赘述。
表2. 每个warp做4次32×32×16 MMA的情况下可行性分析
| MMA_M | MMA_N | MMA_K | MMA per warp | Block per MP | Thread per block | Warp per block | Reg per block | Local mem per block | 可行性? |
|---|---|---|---|---|---|---|---|---|---|
| 32 | 32 | 16 | 4 | 1 | 1024 | 8 | 38912 | 16384 | TRUE |
| 32 | 32 | 16 | 4 | 2 | 1024 | 8 | 38912 | 16384 | TRUE |
| 32 | 32 | 16 | 4 | 3 | 1024 | 8 | 38912 | 16384 | FALSE |
| 32 | 32 | 16 | 4 | 4 | 1024 | 8 | 38912 | 16384 | FALSE |
| 32 | 32 | 16 | 4 | 5 | 1024 | 8 | 38912 | 16384 | FALSE |
| 32 | 32 | 16 | 4 | 6 | 1024 | 8 | 38912 | 16384 | FALSE |
| 32 | 32 | 16 | 4 | 12 | 512 | 4 | 22528 | 8192 | FALSE |
| 32 | 32 | 16 | 4 | 24 | 256 | 2 | 14336 | 4096 | FALSE |
| 32 | 32 | 16 | 4 | 48 | 128 | 1 | 10240 | 2048 | FALSE |
经过作者实际测试,本文最后选择的是表3所示的参数组合,即每个MP贮存1个block,每个block有8个warp,每个warp做8次32×32×16 MMA。但是作者认为该参数组合并不是最优秀的选择,只是受限于作者的水平选出的一个局部最优,希望读者可以根据自己判断多多实践尝试。
表3. 最终选择的参数组合
| MMA_M | MMA_N | MMA_K | MMA per warp | Block per MP | Thread per block | Warp per block | Reg per block | Local mem per block | 可行性? |
|---|---|---|---|---|---|---|---|---|---|
| 32 | 32 | 16 | 8 | 1 | 1024 | 8 | 77824 | 16384 | TRUE |
3.2 向量化读写(40TFLOPS)
向量化读写的核心思想是用连续的、大块的批量读写代替间断的、琐碎的读写。这是一个很自然的想法,因为从硬件的角度来说,连续的读写更有利于全局内存的预读取,大块的读写则有利于缓存行的命中。
具体来说,如图4所示,从全局内存中一次读取256×16=4096个half,而一个block中存在1024个thread,因此每个thread需要搬运4096/1024=4个half。我们可以把程序写作:
#define LDST64BITS(value) (reinterpret_cast<float2*>(&(value))[0])
#define LDST64BITS_CONST(value) (reinterpret_cast<const float2*>(&(value))[0])
LDST64BITS(local_memory.ab.a[local_a_addr]) = (LDST64BITS_CONST(A[gmem_a_addr]));
这样便能够一次性读取4个half,1024个thread一次性就能将所有4096个half数据抓取回来。经过测试,实际上不定义宏,直接使用memcpy也是可行的。
此处,还需要注意的是矩阵在全局内存中的主序问题。本文使用的全部是列主序。图4中橙色的渐变部分展示了列主序矩阵在内存中的连续排布,即颜色连续代表内存空间中排布连续。可以注意到列主序的排布是利好A矩阵的读写的,因为内存空间中连续的数据块大。反观B矩阵,每次读取连续的部分都只有16个half,无法利用GPU缓存行的大小,每次读取都有部分数��据是多余连带上的,这个问题在下文中也会提及。所以GEMM中,我们会更期望B矩阵会是行主序矩阵,会得到更好的性能表现,但如果企图先做主序调整再进行计算其实是更得不偿失的,也有悖算子融合的思想。
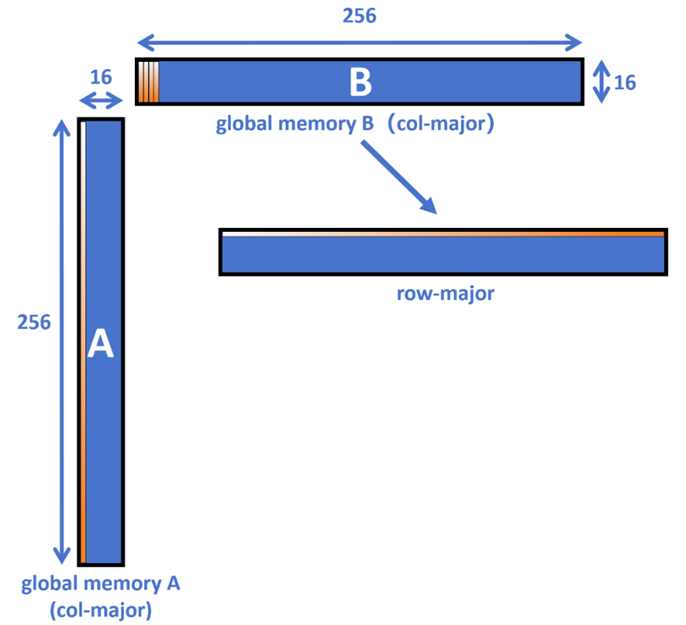
图4. 单次读取Local memory A、B示意图
在完成前面介绍的这两步之后,我们可以得到40TFLOPS左右的性能,相比基线结果10TFLOPS相比已经获得了很大提升。
3.3 Bank conflict消解(42TFLOPS)
如果说向量化读取是为了提高全局内存读写效率,那么Bank conflict消解就是为了提高本地内存读写效率。S4000的本地内存分为32个可以并行访问的bank,每个bank可以提供32 bit 数据的读写,意味着如果能总是同时命中32个 bank,那么一次性最多能读写32×32=1024 bit 即64个half,就能提高本地内存的读写效率。
通常来说,Bank conflict消解主要有两种方式:
- 一种是padding,通过在每一行矩阵末端填充内存实现偏移使得单次读写命中不同的 bank;
- 一种是XOR,在读写本地内存之前就将数据错开放置,使得后续操作能命中全部的 bank。
但是截至目前,MUSA SDK只提供WMMA库,在从本地内存读取到寄存器的时候没法细粒度地控制读取规则。此外,在本地内存充足的情况下,也没有必要使用XOR用复杂的地址计算换取空间,所以在这里我们使用第一种padding的方法来消除bank conflict。
首先分析在什么地方涉及到了本地内存的读写。
- 全局内存A、B到本地内存A、B有一次写操作。但是这个操作过程对于本地内存的写入操作总是打满了所有bank,吃满了全部的本地内存带宽,所以不存在bank conflict的问题。
- 本地内存A、B到寄存器A、B有一次读操作。这里会存在问题,一会做具体分析。
- 寄存器C落回本地内存C有一次写操作。首先,寄存器C的数值精度是float即每个数字正好对应1个bank,对于16×16的子块来说,由于单次连续写入大小只有16个float,打不满全部的bank,会存在bank conflict问题。但是对于使用32×32的子块来说,32个float总是能打满全部的bank,因此不存在bank conflict问题。
- 最后本地内存C写回全局内存C有一次读操作。和1的情况一样,这个操作也是打满了所有的bank,不存在bank conflict的问题。
综上所述,我们只有在情况2中会遇到 bank conflict。如图5所示,在列主序的默认情况下,大小为32×16的Fragment A在读取Local memory A时总是会在Bank0-15(绿色)中进行请求,因此bank16-31(橙色)始终处于空闲状态。
而对于Fragment B读取Local memory B的过程来说,由于数据在Local memory B中总是连续排布的,因此始终能够用满全部的bank,没有bank conflict,不需要额外处理。
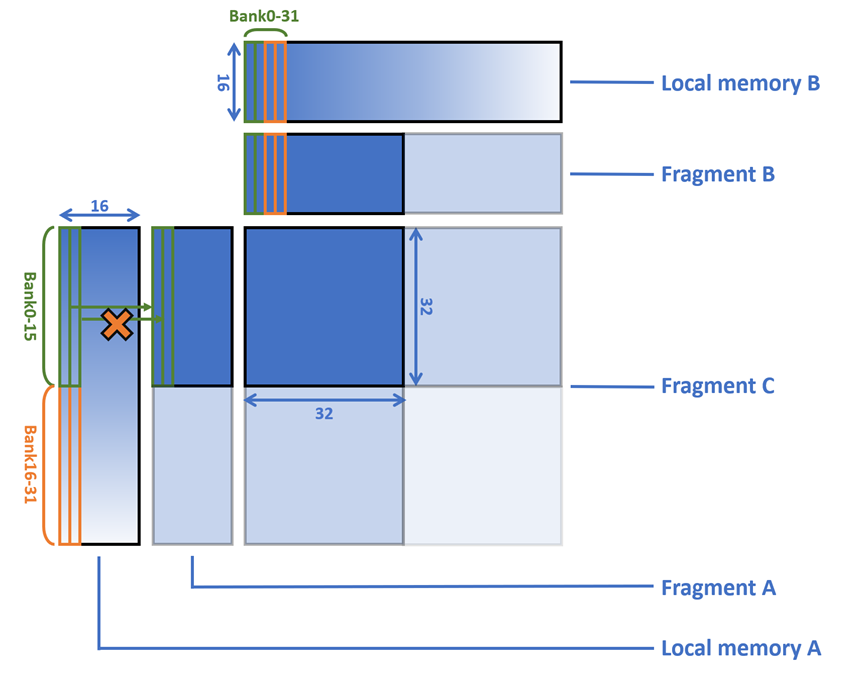
图5. bank conflict分析
为了解决Local memory A的 bank conflict 问题,我们可以采用如图6所示的padding方法,通过往Local memory A的列末端填充占位的空数组,我们可以让bank服务的位置产生32个half的偏移。这样之后,Fragment A在读取Local memory A的过程中就总是能同时命��中全部的32个bank。实际测试下,大约能够获得2TFLOPS的提升,HGEMM的性能也来到了42TFLOPS。
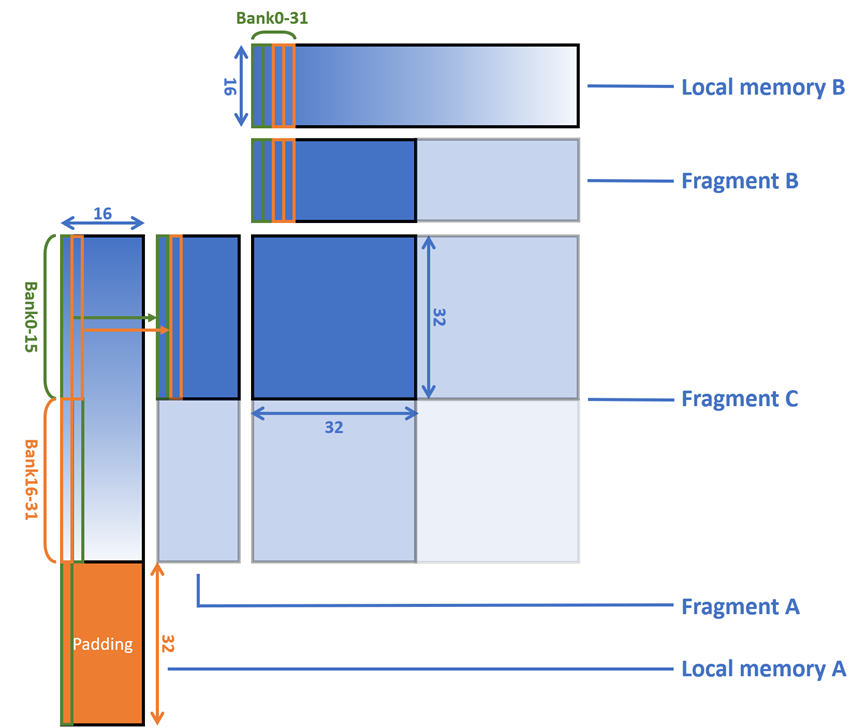
图6. Padding解决bank conflict
3.4 Block swizzling(45TFLOPS)
在前面两部分,我们完成了对全局内存和本地内存读写的优化工作,但还未对针对缓存做任何处理。事实上缓存的命中效率也会极大影响HGEMM算法的工作效率。
那么如何提高缓存的命中效率呢?一言以蔽之:增加时空局部性,即共享缓存的不同MP单元要处理相邻的block块,它们之间会有公用的A、B矩阵数据可以共享。我们虽然无法手动指定让某个MP去做某个block计算,但是我们可以间接地通过发布连续相邻的block计算任务来实现这一点。
如图5所示,默认情况下编译器会按照灰色的箭头来分发block任务给MP,即以grid.x方向遍历到头,然后grid.y增1,再遍历grid.x,此种循环往复的方式完成block任务发布。但是这种发布方式存在空间局部性不强的问题,尤其是在grid.x到头之后的一个猛回头,完全破坏了空间局部性。当然,也可以尝试S型走线,获得一定的空间局部性。但实际效果最好的是swizzling这样的走线方式,空间局部性最好。
一个实现了block swizzling,可供参考的代码:
主机端:
const int N_SWIZZLE = (N + (512) - 1) / (512);
dim3 grid((N/BN)/N_SWIZZLE, M/BM, N_SWIZZLE);
设备端:
const int bx = blockIdx.z * gridDim.x + blockIdx.x;
const int by = blockIdx.y + (blockIdx.z & 1) * (gridDim.y - 1 - 2 * blockIdx.y);
其中M=N=8192,BM=BN=256,N_SWIZZLE的大小是超参数可以手动调节。实际测试下,Block swizzling策略让性能提升了大约3TFLOPS,HGEMM性能来到了45TFLOPS。
顺带一提,此处可能有读者选择使用if判断来分类讨论by的自增方向。这种整个warp走同一分支并不会造成性能影响,但是如果涉及不同的thread需要执行不同的分支就会产生分支发散,MP需要完整执行所有分支来获得结果,导致效率低下。在无法避免的情况下,可以考虑使用上面的这种“谓词执行”的写法,来获得性能提升。
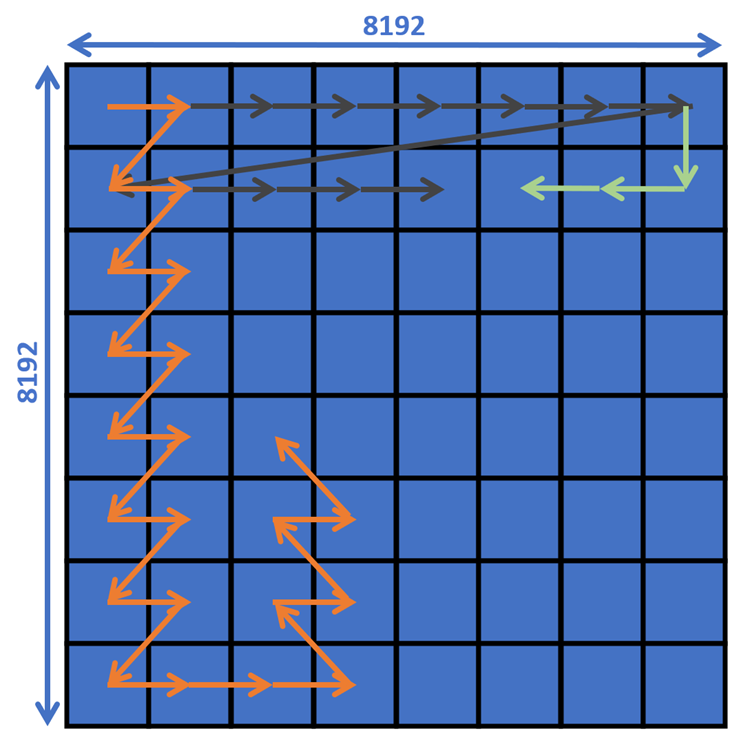
图7. 正常遍历(灰色)、S型遍历(绿色) 和Block swizzling(橙色)示意图
3.5 双(多)缓冲(47TFLOPS)
实现多级缓冲依靠软件流水线,主要使用异步读取数据的方式来手动控制计算和访存的重叠。而根据了解,异步访存的频率大约是同步读取的1/4,只有在读取的块大小是原先4倍的情况下,s4000上的异步读取才能发挥出足够的性能。异步的搬运的另一个好处是,数据不需要再流经寄存器,可以缓解寄存器的压力。
以双缓冲为例,双缓冲的伪代码如下:
- 先声明寄存器(Frag C)和本地内存(Local memory A、B、C),并将Frag C置零。
- 异步读取全局内存
G_A[0、G_B[0],存入本地内存L_A[0]、L_B[0]。 - 同步等待 Step2 完成。
- 异步读取全局内存
G_A[k+1]、G_B[k+1],存入本地内存L_A[k+1]、L_B[k+1]。 - 读取本地内存
L_A[k]、L_B[k],存入寄存器F_A[k]、F_B[k]。(此处简化表示,实际上没必要一次性全放入寄存器中。) - 调用wmma库,完成
F_A[k]、F_B[k]的 mma 累加计算,结果落回Frag C(使用单精度做累加保证计算精度,因此这里的Frag C的数值类型是单精度)。 - 同步等待 Step4 完成。
- 循环重复Step4、5、6、7。
- 将Frag C落回本地内存Local memory C。
- 将Local memory C的数值类型转换为半精度,落回全局内存。
作者所使用的异步读取的指令如下:(但此处有待读者再做验证,根据作者测试似乎此并没有真正实现异步,速度和直接使用同步读取时类似的,删除 commit() 和 wait_prior()似乎也不对代码的运行速度和正确性产生影响。)
__pipeline_memcpy_async(&share_memory[?], &B[?], 8);
__pipeline_commit();
__pipeline_wait_prior(0);
不过在实现了双缓冲之后,代码运行效率确实有2TFLOPS的提升,不过作者认为应当不是异步读取的功劳,而是硬件调度器通过切换不同的warp运行实现了计算和访存的重叠。
3.6 增大K步长(50TFLOPS)
增大K步长的好处是直观的,更大的K步长可以减少__syncthreads() 的使用次数,而此函数对性能的影响其实是显著的。因此如果K步长翻到原来的4倍,就能减少75%的__syncthreads()的使用,从而极大地提升性能。
另外在读取B矩阵的时候,由于B矩阵是列主序,且每次在K维度上只读取16个half即32byte,而GPU中一个缓存行有128byte,所以如果只读取其中的 32byte 是会极大浪费缓存行的,因此此处我们需要读取4倍的原先大小,利用满缓存行。这也是前文中提到列主序的B矩阵的坏处之一。
先看代码逻辑:
- 先��声明寄存器(Frag C)和本地内存(Local memory A、B、C),并将Frag C置零。
- 读取全局内存
G_A[k~k+4]、G_B[k~k+4],存入本地内存L_A[k~k+4]、L_B[k~k+4]。 - 读取本地内存
L_A[k~k+4]、L_B[k~k+4],存入寄存器F_A[k~k+4]、F_B[k~k+4]。(此处简化表示,实际上没必要一次性全放入寄存器中) - 调用wmma库,完成
F_A[k~k+4]、F_B[k~k+4]的 mm a累加计算,结果落回Frag C。 - 循环重复Step2、3、4。
- 将Frag C落回本地内存Local memory C。
- 将Local memory C的数值类型转换为半精度,落回全局内存。
经过测试,此种方案相比使用双缓冲对性能有大约5TFLOPS的提升,因此作者最后放弃了双缓冲,转而使用了此种大批量同步访存降低 __syncthreads()的方案。此处主要实现代码如下:
#pragma unroll
for (int k = 0; k < NUM_K_TILES; k=k+BATCH) {
//G_A --> L_A
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_a_k = (k+t) * WMMA_K + load_smem_a_k;
int load_gmem_a_addr = load_gmem_a_m + load_gmem_a_k * M;
LDST64BITS(share_memory.ab.a[t][load_smem_a_k][load_smem_a_m]) = (LDST64BITS_CONST(A[load_gmem_a_addr]));
}
//G_B --> L_B
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_b_k = (k+t) * WMMA_K + load_smem_b_k;
int load_gmem_b_addr = load_gmem_b_k + load_gmem_b_n * K;
LDST64BITS(share_memory.ab.b[t][load_smem_b_n][load_smem_b_k]) = (LDST64BITS_CONST(B[load_gmem_b_addr]));
}
__syncthreads();
fragment<matrix_b, WMMA_M, WMMA_N, WMMA_K, half, col_major> B_frag[WARP_TILE_N]; //循环内声明,降低寄存器使用,此处带来约0.5TFLOPS性能提升
fragment<matrix_a, WMMA_M, WMMA_N, WMMA_K, half, col_major> A_frag;
#pragma unroll
for (uint t = 0; t < BATCH; ++t) {
#pragma unroll
for (uint i = 0; i < WARP_TILE_N; ++i) {
load_matrix_sync(B_frag[i], &share_memory.ab.b[t][warp_n + i * WMMA_N][0], BK);
#pragma unroll
for (uint j = 0; j < WARP_TILE_M; ++j) {
load_matrix_sync(A_frag, &share_memory.ab.a[t][0][warp_m + j * WMMA_M], BM+OFFSET);
mma_sync(C_frag[j][i], A_frag, B_frag[i], C_frag[j][i]);
}
}
}
__syncthreads();
}
3.7 奇偶切换读取顺序(53TFLOPS)
在上一步中,有一个细节问题,在读取G_A和G_B的时候,应当如何读取?第一时间能想到两种方案:
- 循环读
G_A[k]、G_B[k],再做计算。即一个K步长内按此顺序读取执行:G_A[0]、G_B[0]、G_A[1]、G_B[1]、G_A[2]、G_B[2]、G_A[3]、G_B[3]、mma计算 - 循环读
G_A[k],循环读G_B[k],再做计算。即一个K步长内按此顺序执行:G_A[0]、G_A[1]、G_A[2]、G_A[3]、G_B[0]、G_B[1]、G_B[2]、G_B[3]、mma计算
实际上为了缓存的命中效率,总是连续读取同一块地址�的效率会更高。因此,第二种方案的效果是更佳的,这也是上一步中所采用的策略。其实,再沿着这个思路更进一步,是否有办法能将此策略的效率推向极致?我们发现如果采用方案二的实现,那么在第k轮的末尾读取的是G_B,而第k+1轮的开头读取的是G_A,此处如果k+1轮开头和k轮末尾读取的是同一块矩阵,效果肯定会更好。因此我们可以根据轮次的奇偶性判断此轮应该先读G_A还是G_B,从而总是连续读取同一块矩阵,提高缓存的命中效率。
一个基础实现版本如下:
if ((k / BATCH) % 2 == 0) { //此��处BATCH=4,即一个循环中读取16*4的k大小。先读B再读A。
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_b_k = (k+t) * WMMA_K + load_smem_b_k;
int load_gmem_b_addr = load_gmem_b_k + load_gmem_b_n * K;
LDST64BITS(share_memory.ab.b[t][load_smem_b_n][load_smem_b_k]) = (LDST64BITS_CONST(B[load_gmem_b_addr]));
}
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_a_k = (k+t) * WMMA_K + load_smem_a_k;
int load_gmem_a_addr = load_gmem_a_m + load_gmem_a_k * M;
LDST64BITS(share_memory.ab.a[t][load_smem_a_k][load_smem_a_m]) = (LDST64BITS_CONST(A[load_gmem_a_addr]));
}
} //先读A再读B。
else{
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_a_k = (k+t) * WMMA_K + load_smem_a_k;
int load_gmem_a_addr = load_gmem_a_m + load_gmem_a_k * M;
LDST64BITS(share_memory.ab.a[t][load_smem_a_k][load_smem_a_m]) = (LDST64BITS_CONST(A[load_gmem_a_addr]));
}
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_b_k = (k+t) * WMMA_K + load_smem_b_k;
int load_gmem_b_addr = load_gmem_b_k + load_gmem_b_n * K;
LDST64BITS(share_memory.ab.b[t][load_smem_b_n][load_smem_b_k]) = (LDST64BITS_CONST(B[load_gmem_b_addr]));
}
}
但是上面这种方式存在代码冗余,if开销大的问题。下面的代码使用了逻辑折叠和谓词执行,速度实测会更优,更稳定一些:
bool flag = (k / BATCH) % 2 == 0;
#pragma unroll
for (int i = 0; i < 2; ++i) {
bool load_type_a = (i == 0) ? flag : !flag;
if (load_type_a) {
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_a_k = (k + t) * WMMA_K + load_smem_a_k;
int load_gmem_a_addr = load_gmem_a_m + load_gmem_a_k * M;
LDST64BITS(share_memory.ab.a[t][load_smem_a_k][load_smem_a_m]) = (LDST64BITS_CONST(A[load_gmem_a_addr]));
}
} else {
#pragma unroll
for (int t = 0; t < BATCH; ++t) {
int load_gmem_b_k = (k + t) * WMMA_K + load_smem_b_k;
int load_gmem_b_addr = load_gmem_b_k + load_gmem_b_n * K;
LDST64BITS(share_memory.ab.b[t][load_smem_b_n][load_smem_b_k]) = (LDST64BITS_CONST(B[load_gmem_b_addr]));
}
}
}
此处的优化最终带来了3TFLOPS的提升。
3.8 面向编译器优化(59TFLOPS)
最后是面向编译器的优化,我们之前所做的一切都是在和编译器打交道,编译器就像一个翻译官,把我们下达的指令翻译转述给硬件听。因此我们下达指令准确与否和编译器自身的翻译能力共同决定了最终硬件的执行效率。
执行编译器优化,首先是通用的C++语言编译器的优化设置。
- 默认使用O3级别。此外也有MUSA针对矩阵乘法专门实现的Od3级别,但作者实测效果一般,读者可自行尝试。
- 我们在传入设备端的函数时给出了A、B、C三个矩阵在全局内存的指针,我们事先知道这三个指针都是独占访问的,不会和别的指针指向同一块内存,所以我们可以在A、B、C这三个指针上添加
__restrict__标记,告诉编译器可以大胆优化。这样设置之后可以获得大约0.5TFLOPS的性能提升。 - 我们在声明本地内存时,可以使用
__align__(64)手动设置内存对齐,理论上能让数据够更好地在内存中排布,提高读写效率,但经过作者测试没有特别的作用。 - 在循环体之前使用循环展开 #pragma unroll,减少指令地址的循环跳转,以获得更好的指令执行性能。
其次是MUSA SDK提供的优化选项。 - 在设备端函数前添加
__attribute__((mtgpu_tiny_offset))内核属性,这个属性可以附加到内核函数定义上,以提示编译器该内核中的内存访问操作的偏移量不会超过INT_MAX,以创造更多的优化机会。实测大约能获得2TFLOPS的性能提升。 - 在设备端函数前添加
__attribute__((mtgpu_enable_ldma_index))内核属性。实测获得1TFLOPS的性能提升。 - 还有一些其他的内核属性可供调整,例如
mtgpu_enable_ldlms_opt、mtgpu_workgroup_atomic、mtgpu_num_usreg(256)、mtgpu_unroll_threshold(400)等,读者可以手动尝试修改优化一下。作者在这几项属性上的调整反正是没有带来显著性能提升的。 - 设置
__launch_bounds__(1024, 1),明确告知编译器你想在一个MP单元上启动多少个线程,多少个block。虽然在本例中对性能没有影响,但是在例如硬件支持(512,2)但你想用(512,1)的情况下会有大作用。 - 编译器版本升级。作者最初使用的MCC编译器版本较低,在升级到最新版本之后代码的执行效率得到了5TFLOPS左右的显著提升,HGEMM的最终性能也来到了58.5TFLOPS。
至此我们完成了作者所能实现的全部的代码优化。
最后附上完整的HGEMM代码:
完整代码:
#include <musa_runtime.h>
#include <musa_fp16.h>
// 包含 WMMA API 头文件
#define __MUSA_INCLUDE_COMPILER_INTERNAL_HEADERS__
#include <crt/mma.h>
#undef __MUSA_INCLUDE_COMPILER_INTERNAL_HEADERS__
#define LDST64BITS(value) (reinterpret_cast<float2*>(&(value))[0])
#define LDST64BITS_CONST(value) (reinterpret_cast<const float2*>(&(value))[0])
#define LDST128BITS(value) (reinterpret_cast<float4*>(&(value))[0])
#define LDST128BITS_CONST(value) (reinterpret_cast<const float4*>(&(value))[0])
#define WARP_SIZE 128
#define WMMA_M 32
#define WMMA_N 32
#define WMMA_K 16
#define WMMA_TILE_M 2
#define WMMA_TILE_N 4
#define WARP_TILE_M 4
#define WARP_TILE_N 2
#define OFFSET 2
#define A_LDST_TILE (64 / 16)
#define B_LDST_TILE (64 / 16)
#define BATCH 4
#define BM 256
#define BN 256
#define BK 16
using namespace mtmusa::wmma;
__global__
//__attribute__((mtgpu_enable_ldlms_opt))
__attribute__((mtgpu_enable_ldma_index))
__attribute__((mtgpu_workgroup_atomic))
__attribute__((mtgpu_num_usreg(256)))
__attribute__((mtgpu_tiny_offset))
__attribute__((mtgpu_unroll_threshold(400)))
__launch_bounds__(1024, 1)
void gemm_kernel(
half const* __restrict__ A,
half const* __restrict__ B,
half* __restrict__ C,
int M, int N, int K)
{
const uint NUM_K_TILES = K / WMMA_K;
const uint bx = blockIdx.z * gridDim.x + blockIdx.x;
const uint by = blockIdx.y + (blockIdx.z & 1) * (gridDim.y - 1 - 2 * blockIdx.y);
__shared__ union {
struct {
half a[BATCH][BK][BM + OFFSET];
half b[BATCH][BN][BK];
} ab;
float result[WMMA_TILE_M * WMMA_TILE_N * WMMA_M * WMMA_N];
} share_memory;
const uint lane_id = threadIdx.x; // 0~127
const uint tid = threadIdx.y * blockDim.x + lane_id; // 0~1023
const uint warp_m = (threadIdx.y / WMMA_TILE_N) * (WMMA_M * WARP_TILE_M);
const uint warp_n = (threadIdx.y % WMMA_TILE_N) * (WMMA_N * WARP_TILE_N);
constexpr uint a_col_need_num = BM / A_LDST_TILE;
const uint load_smem_a_k = tid / a_col_need_num;
const uint load_smem_a_m = (tid % a_col_need_num) * A_LDST_TILE;
constexpr uint b_col_need_num = BK / B_LDST_TILE;
const uint load_smem_b_n = tid / b_col_need_num; // 0~63 行
const uint load_smem_b_k = (tid % b_col_need_num) * B_LDST_TILE;
const uint load_gmem_a_m = by * BM + load_smem_a_m; // global m
const uint load_gmem_b_n = bx * BN + load_smem_b_n; // global n
fragment<accumulator, WMMA_M, WMMA_N, WMMA_K, float> C_frag[WARP_TILE_M][WARP_TILE_N];
#pragma unroll
for (uint i = 0; i < WARP_TILE_M; ++i) {
#pragma unroll
for (uint j = 0; j < WARP_TILE_N; ++j) {fill_fragment(C_frag[i][j], 0.0);}
}
#pragma unroll
for (uint k = 0; k < NUM_K_TILES; k=k+BATCH) {
bool flag = (k / BATCH) % 2 == 0;
#pragma unroll
for (uint i = 0; i < 2; ++i) {
bool load_type_a = (i == 0) ? flag : !flag;
if (load_type_a) {
#pragma unroll
for (uint t = 0; t < BATCH; ++t) {
uint load_gmem_a_k = (k + t) * WMMA_K + load_smem_a_k;
uint load_gmem_a_addr = load_gmem_a_m + load_gmem_a_k * M;
LDST64BITS(share_memory.ab.a[t][load_smem_a_k][load_smem_a_m]) = (LDST64BITS_CONST(A[load_gmem_a_addr]));
}
} else {
#pragma unroll
for (uint t = 0; t < BATCH; ++t) {
uint load_gmem_b_k = (k + t) * WMMA_K + load_smem_b_k;
uint load_gmem_b_addr = load_gmem_b_k + load_gmem_b_n * K;
LDST64BITS(share_memory.ab.b[t][load_smem_b_n][load_smem_b_k]) = (LDST64BITS_CONST(B[load_gmem_b_addr]));
}
}
}
__syncthreads();
fragment<matrix_b, WMMA_M, WMMA_N, WMMA_K, half, col_major> B_frag[WARP_TILE_N];
fragment<matrix_a, WMMA_M, WMMA_N, WMMA_K, half, col_major> A_frag;
#pragma unroll
for (uint t = 0; t < BATCH; ++t) {
#pragma unroll
for (uint i = 0; i < WARP_TILE_N; ++i) {
load_matrix_sync(B_frag[i], &share_memory.ab.b[t][warp_n + i * WMMA_N][0], BK);
#pragma unroll
for (uint j = 0; j < WARP_TILE_M; ++j) {
load_matrix_sync(A_frag, &share_memory.ab.a[t][0][warp_m + j * WMMA_M], BM+OFFSET);
mma_sync(C_frag[j][i], A_frag, B_frag[i], C_frag[j][i]);
}
}
}
__syncthreads();
}
const uint warp_id = threadIdx.y * WMMA_M * WMMA_N;
#pragma unroll
for (uint i = 0; i < WARP_TILE_M; ++i) {
#pragma unroll
for (uint j = 0; j < WARP_TILE_N; ++j) {
store_matrix_sync(&share_memory.result[warp_id], C_frag[i][j], WMMA_M, mem_col_major);
#pragma unroll
for (uint step = 0; step < WMMA_M * WMMA_N; step += WARP_SIZE) {
uint c_col = bx * BN + warp_n + j * WMMA_N + (step + lane_id) / WMMA_M;
uint c_row = by * BM + warp_m + i * WMMA_M + lane_id % WMMA_M;
uint c_addr = c_col * M + c_row;
C[c_addr] = __float2half(share_memory.result[warp_id + step + lane_id]);
}
}
}
}
extern "C" void gemm_optimized(
half const* d_A,
half const* d_B,
half* d_C,
int M, int N, int K)
{
const int N_SWIZZLE = (N + (512) - 1) / (512);
dim3 block(128,8,1); // 每个 block 1024 个线程,分成 8 个 warp,每个 warp 128 个线程
dim3 grid((N/BN)/N_SWIZZLE, M/BM, N_SWIZZLE);
gemm_kernel<<<grid, block>>>(d_A, d_B, d_C, M, N, K);
musaDeviceSynchronize();
}
3.9 三点遗憾
3.9.1 分块布局
本文案例中使用1个MP分配一个block,使用1024个thread去计算256×256规模的TILE。但是实际上在和摩尔线程专家交流过后,他们的手写汇编实现(我理解即mublas)中使用的其实是1个MP分配一个block,但只使用512个thread去计算256×256规模的TILE,每个warp去计算128×128规模的TILE。
专家解答:减小线程数的话,单个warp会计算更大的分块,这样以单个warp的视角来看,计算密度是更高的,意味着会获得更高的指令级并行,指令排布有变得更好的机会。更多的线程数只是意味着更高的并发度或者说 occupancy,实际上是依赖SIMT,把优化机会交给硬件调度了。在极致优化的选择上,更好的选择是把主动权握在自己手里。如此布局有希望达到80TFLOPS。
作者也做过相应尝试,但是最终性能却停留在33TFLOPS左右,希望读者可以自行尝试。
3.9.2 持久化block
在本例实现中,我们一次性向显卡发布了(8192×8192)/(256×256)=1024条的block任务,GPU的全局调度器只能按批次把它们扔到MP上去,当一个Block算完自己的Tile,它就退出了,MP的硬件调度器会从等待队列里拉一个新的Block进来。每次分发block任务,都有驱动层开销,硬件上需要做上下文的清理工作,并且我们算子中的一些初始化计算也需要重新完成。更为重要的是MP单元失去了指令级并行的机会,实际上它可以在上一个TILE收尾的时候直接去取下一个TILE所需的数据。最后如果恰巧矩阵维度又不是整数倍,边缘会出现大量只有极少计算量的小Block,全局调度器依然傻傻地启动它们,导致大量MP在那里等这些小Block慢吞吞地算完。(本例中的矩阵维度是整数倍,不存在此问题)
具体实现方式其实很简单,在显存中维护一个计数器,按照S4000的MP单元数(64个)发布block任务,完成当前TILE时就在这个计数器上+1,然后读取当前计数器的数值对应下一步需要计算的TILE即可。Block任务里是一个大循环,计数器的数值和总需要计算的TILE数相等时退出。
作者自然也是不想放弃如此的优化机会,但是经过反复尝试,总是出现寄存器溢出的情况,迫于无奈不得不放弃。
3.9.3 写回处理
在本例实现中,最后的写回部分的实现其实很粗糙,从Fragment写回到Global memory的过程需要两次经过寄存器,效率是比较低的。但好在写回仅发生在最后一部分,并未对性能造成特别显著的影响。理论上更好的方法是不落回Local memory,而是直接由Fragment取值转换然后一步写回Global memory。但是由于我们无法探知计算结果在Fragment中的组织排布情况,所以难以实现上述过程。有耐心的话,作者猜测也许可以构造一个矩阵结果打印出来看看排布情况?
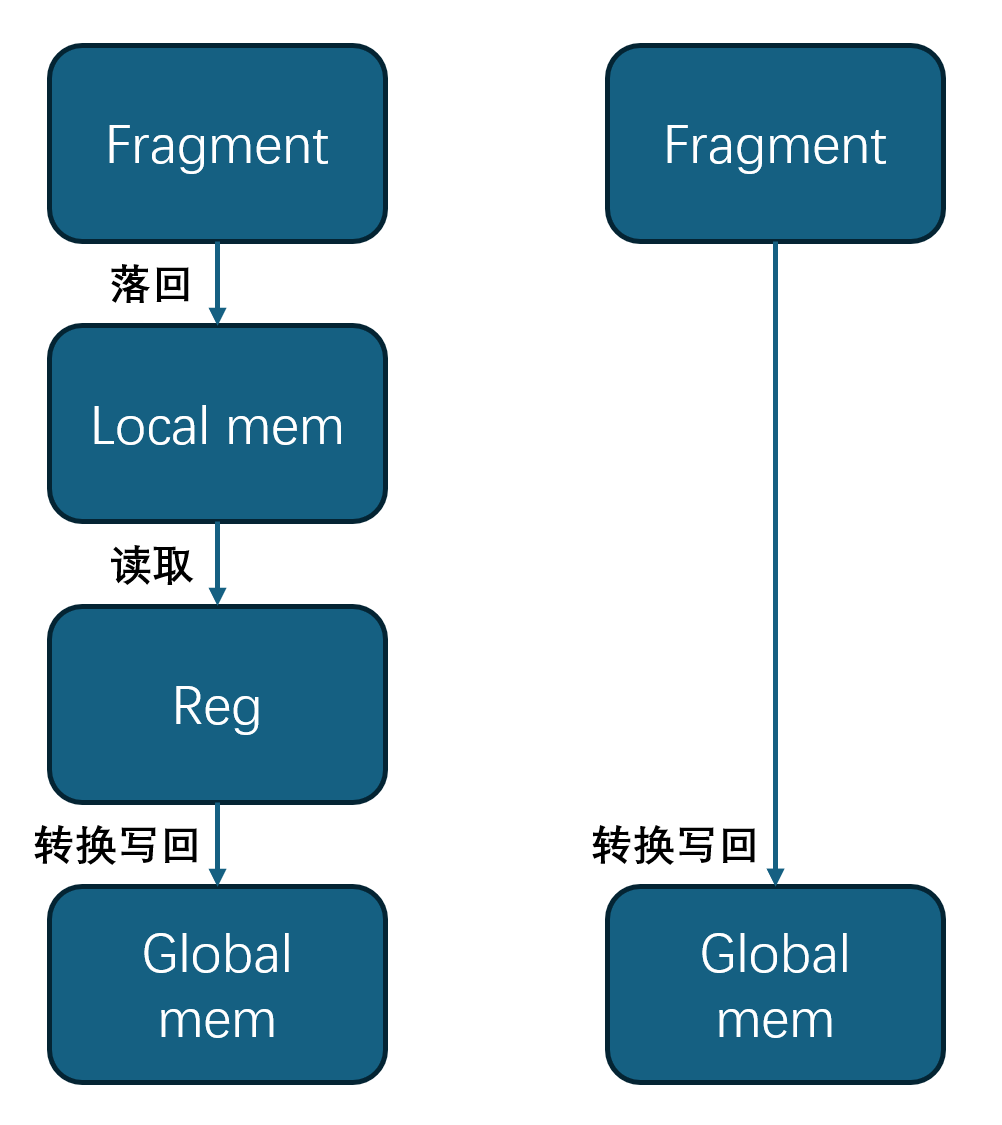
图8. 两种写回方式比较
4. 最后一点奇思妙想
写在最后。真正推动系统向前的,也许不是既定范式内的精细打磨,而是那些看似离经叛道的奇思妙想。真正的突破,往往来自那些敢于在不确定性中前行的尝试,正是这些大胆却有根基的“冒险”,一点点地撬动了性能的上限……
4.1 Warp专用化
了解Flash Attention的同学可能知道,最新的Flash Attention-3中用到了一个异步执行的技术。通过将不同的warp分别指定为计算GEMM和执行softmax实现了流水线并行。那么在GEMM优化中,我们是否也可以借鉴类似的思想?例如,将同一个block中的warp进行角色划分:一部分warp专门负责数据搬运(如从全局内存到本地内存),另一部分warp专注于矩阵乘法计算。理想情况下,这两类warp可以形成一种producer–consumer关系,通过��共享内存作为中介,实现数据加载与计算的重叠,从而进一步提升整体吞吐。
4.2 Hazard,竞争与冒险(63TFLOPS)
熟悉芯片设计的同学可能有所了解,在组合逻辑电路中,由于信号传播延迟不同,会导致逻辑门输出短暂且错误的状态。其实在GPU的并行执行中也存在类似的情况,有的warp会被调度器优先调度执行,有的则可能因为需要等待数据而执行得较为缓慢。因此在关键的部分为了保证一致性我们需要加入__syncthreads()函数来同步block内所有的warp,就和同步时钟电路的时钟信号将逻辑门的最终输出锁定在寄存器中一样。
但同步真的是不可触碰的“安全线”吗?我们能否主动削弱甚至移除它,用可控的不确定性换取更高的性能上限?甚至是否应该尝试打破它——哪怕以确定性为代价?
异步逻辑电路带给我们一种可能,它没有时钟信号,由输入信号的变化直接驱动,依赖各条路径的传播延迟来“自然收敛”到正确状态。换句话说,系统不再等待一个全局的同步点,而是让不同模块在局部条件满足时自行推进,从而实现更细粒度的并行与更高的潜在效率。因此,这种“异步化”的优化,本质上是一种在性能与确定性之间的博弈。
或许真正的关键不在于“去掉同步”,而在于——能否像设计异步逻辑电路一样,建立一套对延迟、依赖与执行顺序的严格约束,使系统即使没有全局时钟,也依然可控、可验证?
所以说了这么多,落在GEMM算子设��计上,我们能做什么呢?
删除完整代码中的第二个__syncthreads(),也许你的心里便有了答案。

