MTT S4000 GEMM 优化中的分块、尾处理与并发实战复盘
1. 规则分析
赛题有以下约束:
| 项目 | 要求 |
|---|---|
| 输入输出 | FP16 输入,FP32 累加,FP16 输出 |
| 固定接口 | extern "C" void gemm_optimized(...),签名不能改 |
| 数据布局 | A/B/C 都按列主序访问 |
| 同步要求 | 返回前必须完成计算,提交版需要 musaDeviceSynchronize() |
| 禁止行为 | 禁止 muBLAS/muDNN 等高层库,禁止修改输入矩阵,禁止投机跳过计算 |
| 评测重点 | correctness 先过,再看 8192 x 8192 x 16384 的性能 |
这组规则对后面的设计有两个直接影响:
- 不能把问题当成普通 CUDA GEMM 直接套模板。
列主序、MUSA WMMA 语义、提交接口和同步位置,都必须一一对齐。 - 性能优化必须和正确性绑定。
任何没有经过完整 correctness 约束的高分版本,最后都可能只是表面上跑得快。
2. GEMM入门
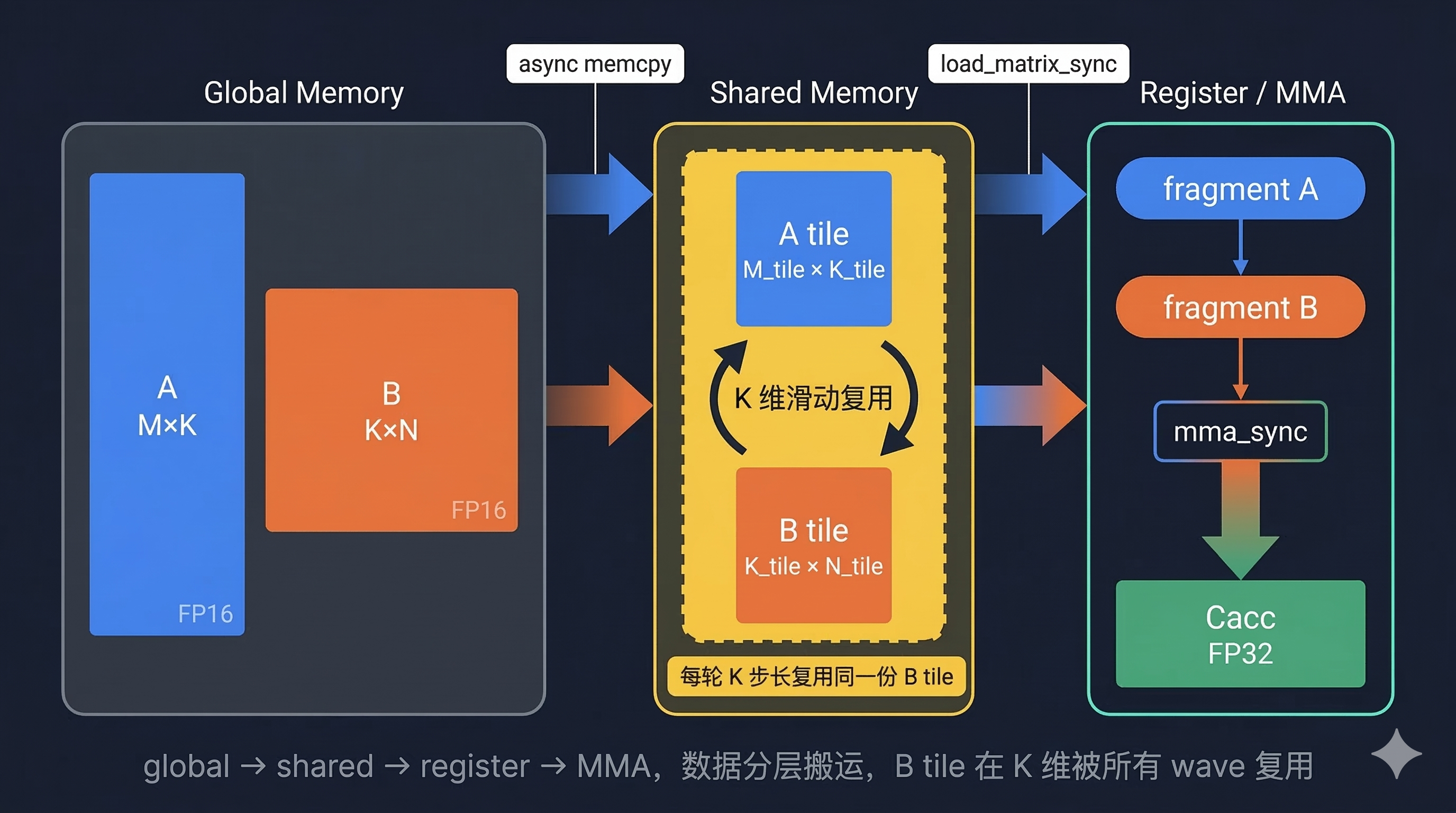
在前期准备阶段, 我主要做了三件事: 先理解 GEMM 的计算本质,再跑通提交代码的最小链路,最后去看 S4000 这张卡真正吃什么。
GEMM 本质上就是一个三重循环:
for (int n = 0; n < N; ++n)
for (int m = 0; m < M; ++m) {
float acc = 0.0f;
for (int k = 0; k < K; ++k)
acc += A[m, k] * B[k, n];
C[m, n] = acc;
}
在固定规模是 8192 x 8192 x 16384 下,单次计算量就是 2 x M x N x K,大约 2.2e12 FLOPs。
由此可以快速得出两个关键结论:
- 不能按教科书式逐元素直算。
如果每次乘加都直接从全局内存读取数据,带宽会迅速成为瓶颈。 - 数据复用是第一原则。
同一块A和B子块会参与很多输出元素的计算,所以 tile、shared memory 和寄存器缓存不是锦上添花,而是基本前提。
这道题还有一个很容易踩坑的地方,就是 列主序。很多人平时更熟悉行主序,但这里地址计算必须统一为:
A(m, k) -> d_A[m + k * M]
B(k, n) -> d_B[k + n * K]
C(m, n) -> d_C[m + n * M]
结合摩尔线程 MTT S4000 的公开规格:
- 48GB GDDR6
- 768GB/s 显存带宽
- FP16/BF16 峰值 100 TFLOPS
这几个数字直接告诉我,想把这道题做好,必须同时满足两件事:
- 主计算必须尽量走 Tensor Core 路径。
否则纯标量或普通向量 FMA 很难逼近这张卡的张量算力上限。 - 访存必须做分层复用。
既然带宽是硬上限,就不能让每个 wave 都反复从 global memory 取同一块B。
MUSA 编程和性能文档里还有几条对这题非常关键的硬件事实:
- MUSA 的存储层次是
register->shared memory->global memory。GEMM 天然适合把数据按global -> shared -> register -> mma这条路径搬运。 - QY 架构下
warpSize=128。block size 通常要取 warp size 的整数倍,128/256/512/1024都是合理候选。 - active warps 并不是越多越好,它会同时受寄存器和 shared memory 用量约束,所以 tile 变大、unroll 变深,未必一定更快。
- double buffer、向量化加载、多 stream 并发,都是有价值的工具,但前提是主核结构已经稳定。
这一阶段最大的收获,是将优化方向从经验判断转变为基于硬件约束的推导。
3. 基础框架搭建
在理清 GEMM 计算和硬件特性后,我开始搭建开发闭环,把代码怎么组织、实验怎么推进、结果怎么判断这三件事做顺。
我把基础框架拆成两层:
- 代码框架:把提交接口、路由、fallback、epilogue 这些骨架搭对。
- 实验框架:把评分、监控、profile、日志、版本快照这套闭环搭起来。
3.1 搭代码框架,再填快路径
Host 侧骨架大致如下:
extern "C" void gemm_optimized(
half const* d_A,
half const* d_B,
half* d_C,
int M, int N, int K) {
if (!fast_ok32(M, N, K)) {
gemm_fallback_kernel<<<grid, block>>>(d_A, d_B, d_C, M , N, K);
musaDeviceSynchronize();
return;
}
if (M == 8192 && N == 8192 && K == 16384) {
gemm_wmma32_wave128x8n128_k16384_k32_reuseB_kernel<<<grid, block, 0, s_epi_stream0>>>(...);
musaEventRecord(s_evt_gemm_done, s_epi_stream0);
musaStreamWaitEvent(s_epi_stream1, s_evt_gemm_done, 0);
fp32_to_fp16_8192_half2x8_oneshot_kernel<<<..., s_epi_stream0>>>(...);
fp32_to_fp16_8192_half2x8_oneshot_kernel<<<..., s_epi_stream1>>>(...);
musaDeviceSynchronize();
return;
}
// 其它尺寸按 x1/x2/x4/x8 路由
...
}
这套代码框架的作用是:
- 避免某个专用 kernel 失败导致整份代码不可用。
- 将优化集中在固定形状的专用路径,不会反复污染通用逻辑。
- 将 correctness 和 performance 解耦分析。
3.2 搭实验框架
每轮实验都固定成下面 6 步:
- 备份当前代码版本。
- 运行
grader,看 correctness 和 GFLOPS。 - 运行
mthreads-gmi,看 utilization / clock / temperature。 - 运行
msys profile,看 API 和 kernel 时间线。 - 保存报告、日志、profile。
- 给这次实验贴标签,方便后面回滚和对比。
这个流程帮我省掉了很多无效尝试。因为当版本一多,最怕的不是性能没涨,而是根本说不清为什么涨、为什么跌。
4. 环境搭建
比赛镜像里提供了评分脚本、编译环境和 profiling 工具。对参赛过程最有用的命令有:
# 相对评分
python3 grader.py <submission>.mu --verbose
# 绝对性能展示
python3 grader_absolute.py <submission>.mu
# 设备状态监控
mthreads-gmi -q -d UTILIZATION,CLOCK,TEMPERATURE -l 1
# 时间线分析
msys profile -d 0 -t musa,osrt --gpu-metrics-set=1 --duration=20 \
-o gemm.msys-rep \
python3 grader.py <submission>.mu --report gemm.json
如果要单独手工编译某个 probe 或最小复现版本,可以跟比赛环境保持一致,固定使用:
mcc --offload-arch=mp_22 -O3 -march=native -lmusart -lmublas
安装 Moore Perf System
官方安装手册给出的 Linux 安装方式非常直接:
sudo dpkg -i moore-perf-system_1.3.0_x86_64.deb
msys --version
工具包可以从官方页面下载:Moore Perf System 下载页。
GPU 设备信息与监控
设备侧主要依赖 mthreads-gmi, 公开文档里能直接找到对应说明:
-
实战命令:
mthreads-gmi -L
mthreads-gmi -q
mthreads-gmi -q -d UTILIZATION,CLOCK,TEMPERATURE -l 1
在比赛环境里,它最适合做粗粒度状态观察,比如看 GPU 有没有真正拉起来,时钟是否稳定,温度是否异常。它不适合做 38 ms 级单 kernel 精细分析,这部分还是要交给 msys。
5. 优化主线
5.1 先把链路跑通
第一次跑通链路: WMMA 的列主序加载 -> FP32 累加-> FP16 写回,性能达到 3.65T。
这一阶段明确了关键接口的使用方式,也暴露了数据排布、精度转换和边界处理这些最容易埋雷的问题。
随着计算组织从单个 WMMA 单元扩展到多 wave,并逐步引入 block tiling、shared memory staging 和数据复用,整体框架开始成型,性能也提升到了 14.07T。
后续问题从 "能不能写出一个正确的 WMMA kernel",推进到了 "该把优化主线押在哪个结构方向上"。
5.2 分块选择
这一轮先收敛下来的,是主核的分块,而不是 stream 数量。
评测固定在 8192 x 8192 x 16384 时,决定上限的核心问题其实很简单:
N方向一个 block 吃多宽K方向按多大的步长往前推
最后把注意力集中在 N64 / N128 / N256 三条路线上,结论很明确:
| 分块路线 | 性能 | 问题 |
|---|---|---|
N64 | 25.8T - 36.3T | 输出条带太窄,B 的装载和同步成本摊不薄 |
N128 | 57.62T | 复用、寄存器压力、occupancy 最平衡 |
N256 | 34T - 48.9T | 累加器和 shared staging 明显变大,资源压力过高 |
N64 的问题不在于算不动,而在于一个 block 只吃 64 列,条带太窄,后面的 epilogue 和调度开销占比都会被放大。
N256 刚好相反,理论上复用更好,但累加器 fragment 数量、shared staging 体积和 loader 压力都会一起往上走,最后先崩的是 occupancy。
最终留下来的主线是:
1024-thread / 8-wave 配 K32 x N128
这个选择没有最夸张的单项指标,但整体最顺。后面所有能冲到 57T 以上的结果,都是在这条主线上继续细化出来的。
5.3 尾处理拆分
主核分块定下来以后,瓶颈随后转移到 epilogue。这个阶段我没有再动主核,只改了 FP32 Cacc -> FP16 C 的组织方式,结果非常直接:
- 拆成两半时能到 57.86T
- 拆成四半降到 57.59T
- 拆成八半继续掉到 57.39T
后面又试了不同的 epilogue block 形状和 launch_bounds,结果也都在 56.5T - 56.9T 这一档。
| 尾处理组织方式 | 典型性能 | 判断 |
|---|---|---|
| 两段拆分 | 57.86T | 最合适,能明显压缩尾部时间 |
| 四段拆分 | 57.59T | 有收益,但开始被拆分开销吃掉 |
| 八段拆分 | 57.39T | 拆得过细,调度成本继续上升 |
| 调整 epilogue block 形状 | 56.90T 左右 | 没有优于两段拆分 |
给 epilogue 增加 launch_bounds | 56.59T - 56.72T | 强行限定形态没有带来正收益 |
这组实验说明两件事。
- 第一,epilogue 不是�一个可以忽略的收尾动作,它已经进入了主路径。
- 第二,这段逻辑也不是拆得越细越好。拆成两半,刚好能把原来那段偏串行的尾部压下去;继续拆,launch、同步和调度的成本就开始反吃收益。
所以后面一直保留的是 split2,没有再往更细的方向走。对这题来说,尾处理最重要的不是追求更复杂的并发,而是别让它重新长成新的瓶颈。
5.4 主核微调
主核优化进入“微调阶段”,主要集中在 wait_prior 的等待时机和轻量的 unroll2。这也是后面判断主核已经接近收敛的依据。
| 主核改动 | 典型性能 | 判断 |
|---|---|---|
wait_prior 微调 + unroll2 | 57.8T 左右 | 最后保留下来的有效组合 |
early prefetch | 57.2T 左右 | 预取更早,不等于重叠更好 |
16B/线程 + 512 loader | 47.98T | loader 结构改动过大,直接退化 |
主核强加 launch_bounds | 40T 出头 | 资源平衡被明显打坏 |
wait_prior 等待时机调紧,再配合 unroll2,性能可以推到 57.8T 左右。
没用甚至明显负收益的改动反而更多:
- 把 loader 改成 16B/线程并缩到 512 loader 线程,会直接掉到 47.98T
- 把 prefetch 前移,成绩大约只有 57.2T
- 主核强行改
launch_bounds,最差时甚至会掉到 40T 出头
这一段最重要的认识是,主核一旦到了高位,后面的优化就不是再去重写结构,而是把流水节奏慢慢磨顺。shared 数据什么时候真正到位,wait_prior 放在哪里,unroll 到什么程度不把寄存器顶爆,这些小地方比看起来更关键。反过来讲,越激进的大改越容易把已经调好的平衡打坏。
5.5 并发拓扑
最后一个收敛点是并发到底该放在哪里。几种常见做法,包括把主核沿 N 方向切成两路、四路,把整张矩阵按行或按列拆开跑双流,甚至做更细的 4096 x 2 流水。结果都不如最后的方案稳定。
| 并发方式 | 典型性能 | 判断 |
|---|---|---|
主核沿 N 方向二分双流 | 56.66T | 能跑,但拆主核的代价偏大 |
| 按行切双流 | 56.13T | 不如保留完整主核 |
| 按列切双流 | 56.43T | 比按行略好,但还是不够 |
| 四流方案 | 54T 左右 | 过度并发,调度成本过高 |
4096 x 2 流水 | 56.4T - 56.6T | 有改善,但没越过主线 |
| 主核单流 + 尾处理双流 | 57.62T | 最终提交结构,最稳 |
- 主核沿
N方向二分,成绩大约 56.66T - 按行或按列切成双流,分别在 56.13T 和 56.43T 左右
- 四流方案基本都会掉到 54T 一档
4096 x 2的顺序流水和双流配对流水,大致在 56.4T - 56.6T
这些做法都能跑,但都没有真正超过主线。
最后采用的结构反而最简单:主核保持单流 + epilogue 拆成双流
原因也很直接:
- 主核是重工作负载,对 tile 复用、shared 访问和调度节奏都很敏感,切碎以后很容易把原本已经调顺的东西重新打乱
- epilogue 更轻,也更规整,适合在主核结束后拆成两路并发去做
6. 最终版本的结构和取舍
最终方案可以总结为:
- 一个 1024 thread block 对应 8 个 waves。
- 每个 wave 负责
32 x 128的输出条带。 - B 的
K32 x N128tile 进入 shared memory,被 8 个 wave 复用。 - 主核输出
FP32 Cacc,epilogue split2 双流把结果转成FP16 C。
这套方案背后体现了三层平衡:
- 计算侧:让 Tensor Core 主核始终是主要工作量承担者;
- 访存侧:把 B 的共享和 K32 步长组织到足够高效;
- 尾处理侧:避免 epilogue 变成新的串行瓶颈。
在优化的过程中,记录了几条淘汰的路线:
- 更大 tile / N256 路线
直觉上像是复用更多,实测经常是寄存器和 occupancy 先出问题。 - 四流拆分路线
2 流还能有效,4 流基本就开始过量并发,收益被调度和竞争吃掉。 - 16B loader / 512 loader 之类的大改访存动作
看起来更激进��,但并不意味着更快。 - 过深的 unroll / 过松或过紧的 wait_prior
这些改动都不是单调有效的,稍微越界就会直接退化。
这些失败样本让我越来越清楚:高性能不是靠把每个方向都做到极致,而是靠只保留那些彼此兼容的优化。
7. 学习总结
我把这次比赛的学习过程总结如下:
- 先搭框架,再做优化。
没有代码框架和实验框架,再多跑分都只是一次性结果。 - 先把问题拆层,再做局部最优。
host 路由、主核、epilogue、profile,这些层次必须先分开。 - 真正有效的优化,往往建立在长期记录的正负样本之上。
wait_prior、unroll、split2、双流这些结论,都是靠大量失败版本反推出来的。 - 工具链本身就是能力的一部分。
grader给分数,mthreads-gmi给设备状态,msys给时间线,没有哪一个可以省。
参考资料
- MTT S4000 产品规格书:Product Specifications
- MUSA 编程基础:Programming Guide Chapter 05
- MUSA 性能优化:Programming Guide Chapter 09
- Moore Perf System 下载页:Moore Perf System
- mthreads-gmi 手册:GPU Management Center User Manual

