使用摩尔线程 GPU 搭建个人 RAG 推理服务
什么是 LLM RAG?
LLM RAG(Retrieval-Augmented Generation with Large Language Models)是一种结合大语言模型(LLM)和信息检索(IR)技术的生成方法,专门用于增强语言模型的上下文感知和准确性。在这种方法中,检索模块从一个外部知识库(例如文档、数据库或向量数据库)中获取相关信息,然后将这些检索到的内容与 LLM 结合,使得生成结果更加精准和信息丰富。
什么是 Ollama?
Ollama 是一个工具和平台,专注于简化和优化大语言模型(LLM)的管理和部署。它主要提供了一种方便的方式,在本地或边缘设备上运行、管理和调用大型语言模型,同时通过其特有的 Docker 集成和 API 接口,使得 LLM 的使用更加灵活、轻量且安全。
Ollama 因为其本地化、轻量级和灵活性,使其成为一种在多个环境中管理和部署 LLM 的理想工具。
什么是 Open WebUI?
Open WebUI 是一个开源项目,致力于创建一个通用的用户界面(Web UI),用于本地化运行和管理大语言模型(LLM)以及其他生成式 AI 模型(例如图像生成模型)。Open WebUI 旨在简化 LLM 和生成式 AI 模型的操作,让用户可以通过一个网页界面快速上手并进行实验,无需复杂的编程或配置。
使用 Ollama + Open WebUI 搭建个人 RAG 服务
准备工作
以下代码运行在 x86 架构的 Ubuntu 20.04/22.04 系统。
配置容器运行时
请参考以下链接安装和配置容器运行时。
- 安装 Docker: Docker 安装指南
- 安装 Docker Compose: Docker Compose 安装指南
- 安装 MTT S80/S3000/S4000 驱动 (当前为 rc3.1.1): MUSA SDK 下载
- 安装 MT Container Toolkit (当前为 v1.9.0): MT CloudNative Toolkits 下载
检查容器运行时配置是否正确,确认输出的默认运行时为 mthreads。
$ (cd /usr/bin/musa && sudo ./docker setup $PWD)
$ docker info | grep mthreads
Runtimes: mthreads mthreads-experimental runc
Default Runtime: mthreads
准备 docker-compose.yml 配置文件
$ export RAG_DIR=$HOME/rag
$ mkdir -p $RAG_DIR
$ cat > $RAG_DIR/docker-compose.yml << 'EOF'
services:
ollama:
image: mthreads/ollama:${OLLAMA_DOCKER_TAG-latest}
pull_policy: always
container_name: ollama
volumes:
- ollama:/root/.ollama
ports:
- ${OLLAMA_PORT-11434}:11434
cap_add:
- SYS_NICE
tty: true
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-latest}
pull_policy: always
container_name: open-webui
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
ports:
- ${OPEN_WEBUI_PORT-3001}:8080
environment:
- 'OLLAMA_BASE_URL=http://ollama:11434'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ollama: {}
open-webui: {}
EOF
通过 Docker Compose 启动 Ollama 和 Open WebUI 容器
$ export RAG_DIR=$HOME/rag
$ docker-compose -f $RAG_DIR/docker-compose.yml up -d
通过上述步骤,您将运行一个 Ollama 容器和一个 Open WebUI 容器。Open WebUI 容器的 8080 端口将映射到主机的 3001 端口,您可以通过浏览器访问 http://localhost:3001 来查看 Open WebUI 的界面。
您可以通过
docker exec -it ollama bash进入 Ollama 容器,然后使用ollama命令行工具来管理和运行大语言模型。 例如:$ docker exec -it ollama bash
root@04b41108d2e4:/# ollama ls
NAME ID SIZE MODIFIED
qwen2.5:latest 845dbda0ea48 4.7 GB 1 days ago
root@04b41108d2e4:/# ollama run qwen2.5
使用 Open WebUI 完成模型下载、知识库准备和推理
下载 Qwen2.5 模型
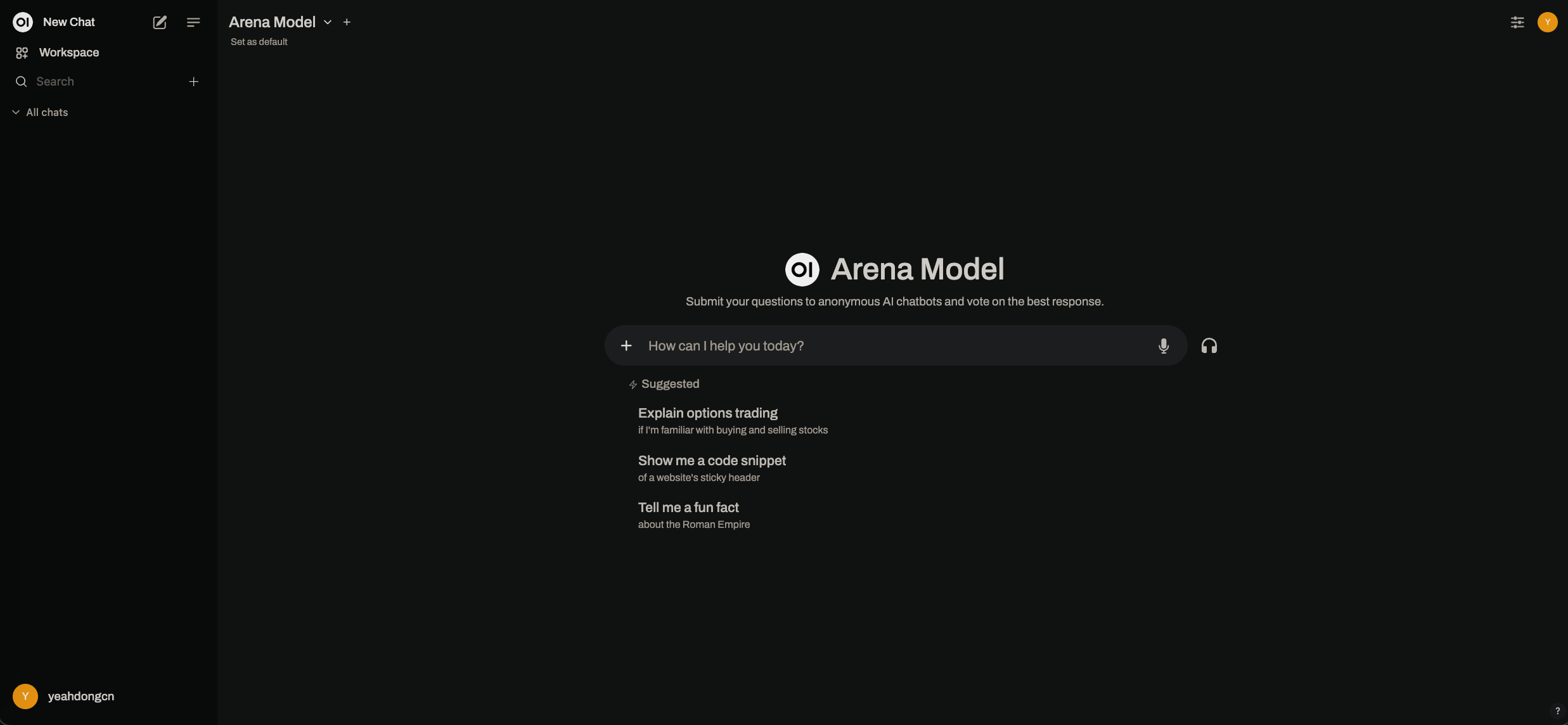
通过 http://localhost:3001 访问 Open WebUI 界面,完成首次的注册和登录操作。登录成功后,您将看到如下界面:
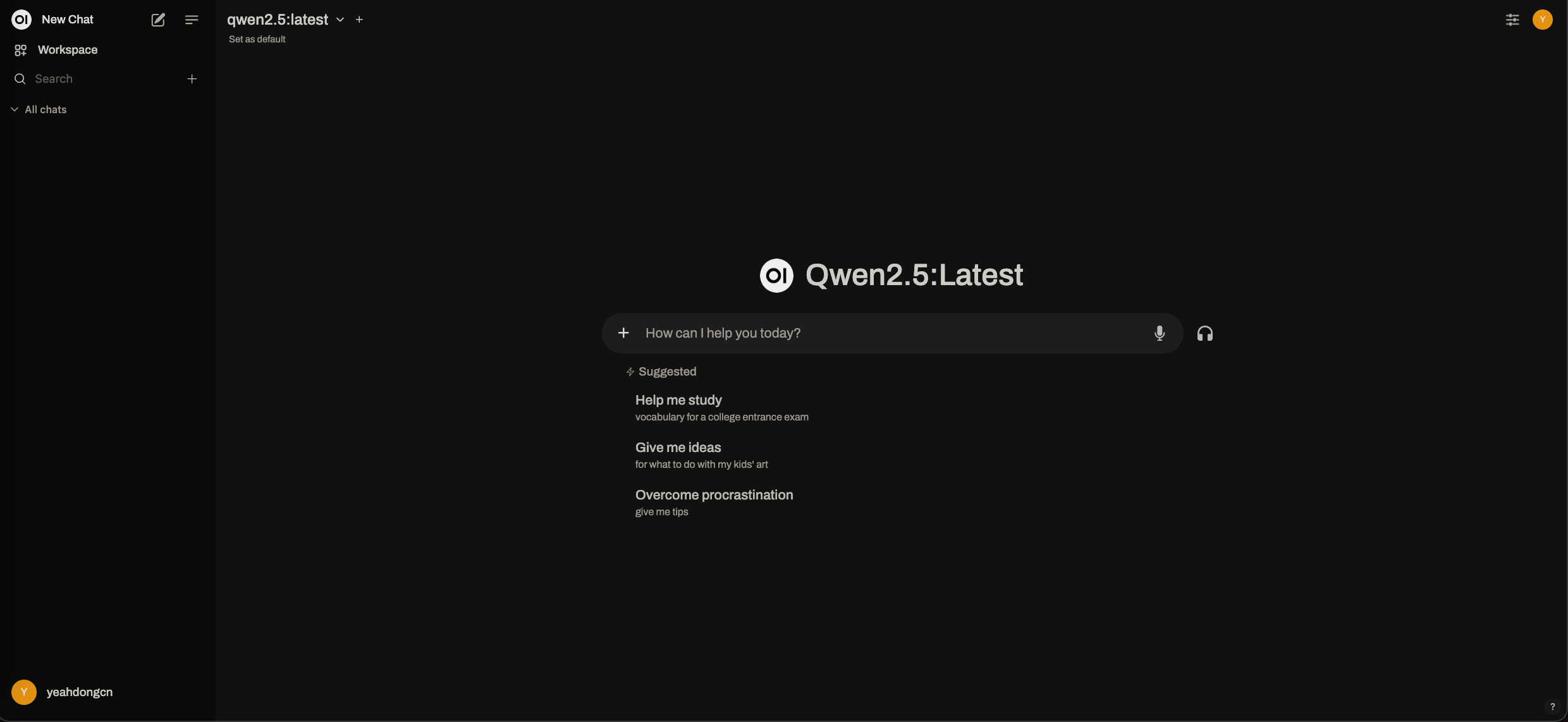
点击模型下拉框,输入 qwen2.5,然后点击 Pull "qwen2.5" from Ollama.com 列表项,等待模型下载完成。下载完成后,选择 qwen2.5 模型,您将看到如下界面:
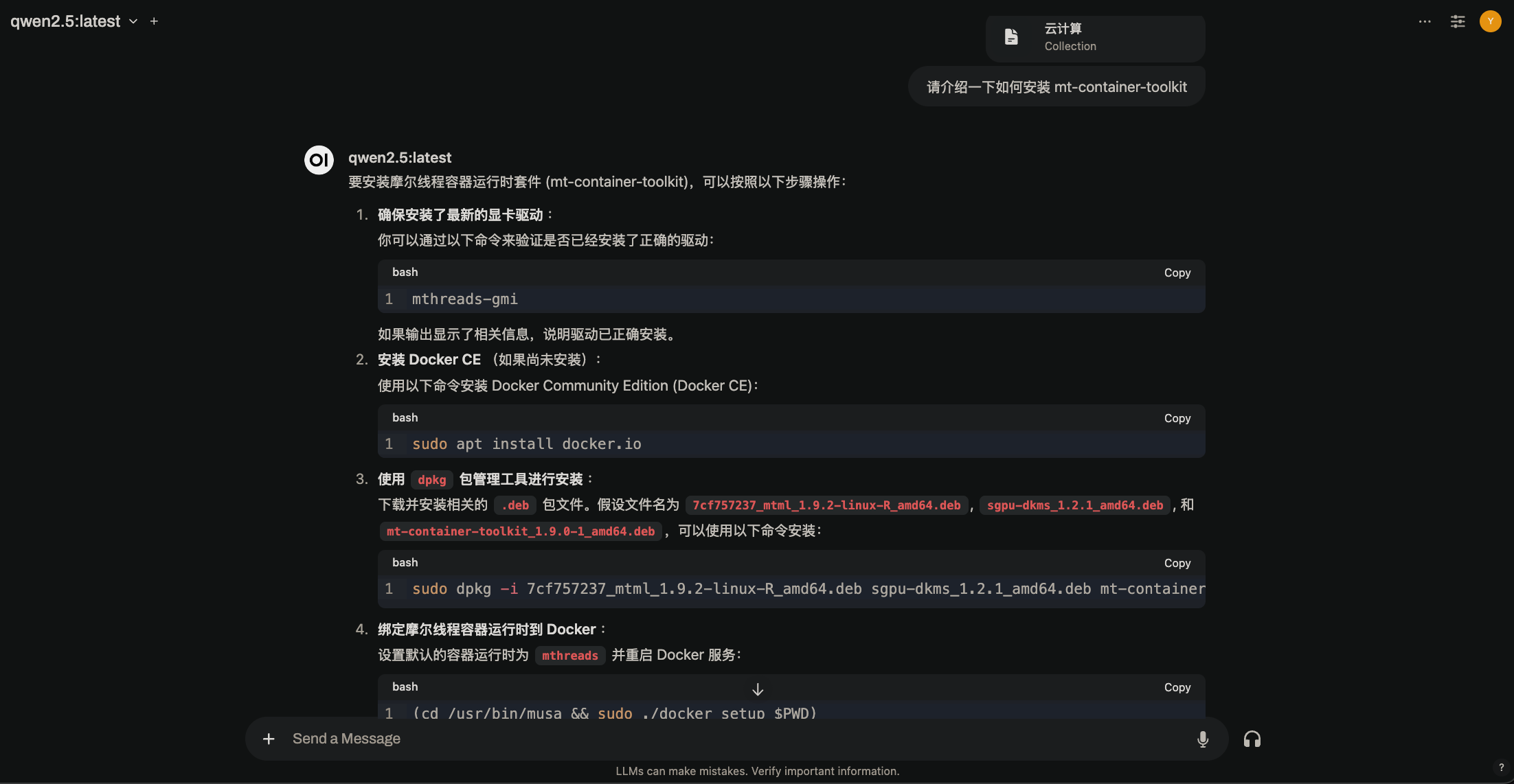
此时,您可以通过 Open WebUI 界面与 Qwen2.5 模型进行对话。Open WebUI 会将您的问题发送给 Ollama 服务进行推理,并将结果返回给您。
准备知识库
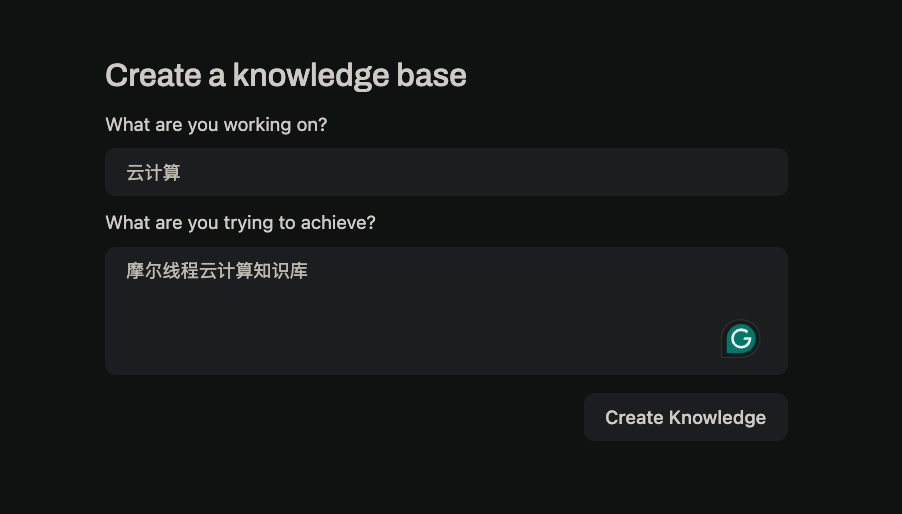
点击 Workspace, Knowledge, + 按钮(在界面的右侧),您可以创建一个新的知识库。在弹出的对话框中,输入知识库的名称和描述,然后点击 Create Knowledge 按钮。
点击搜索框右边的 + 按钮,您可以通过多种方式上传知识库的数据,包括添加文本、上传目录等。上传完成后,您可以在知识库中查看您上传的数据。

成功上传的内容会以文件形式排列在搜索框下方,如下图所示。
使用知识库进行 RAG 推理
点击 New Chat 按钮开始一个新对话,从下拉列表中选择 qwen2.5 作为推理模型。在对话框中输入 # 符号,选择刚刚创建的知识库,然后输入您的问题。Open WebUI 会将问题发送到 Ollama 服务进行推理,并将结果返回给您。