推测解码算法在 MTT GPU 的应用实践
2024-11-25
前言
目前主流的大模型自回归解码每一步都只生成一个token, 尽管kv cache等技术可以提升解码的效率,但是单个样本的解码速度依然受限于访存瓶颈,即模型需要频繁从内存中读取和写入数据,此时GPU的利用率有限。为了解决这种问题,VLLM框架中提出的continues batching的推理方式则是充分利用批量推理来缓解或避免访存瓶颈,极大的提升了推理系统的吞吐量。不同于VLLM等框架在系统层面的加速优化,本文所想要介绍的推测解码(speculative decoding)技术则是聚焦于算法层面的加速优化,其核心想法是借助于更小的模型来并行或者串行生成多个token。
OpenAI 于2024年11月5日提出了 "Predicted Outputs" 特性,在某些情况下,LLM 的大部分输出是事先已知的。例如,如果用户要求模型对某些文本或代码进行仅有少量修改的重写,那么可以通过使用预测输出显著降低延迟,将已有内容作为预测传入。这种技术与prompt-lookup Decoding很相似,即通过匹配prompt中相似的token序列来生成候选token的方法,这种算法的优势是不需要额外的模型来验证候选的token是否是可接受的,但劣势是只适用于特定的任务,即输出大概率在输入中的,如果是翻译任务则大概率会适得其反。因此,"Predicted Outputs" 可以看成是一般性推测解码的一种特殊场景的引用。
对于一般性的推测解码技术而言,目前方法通常都分为两个步骤:一是使用Draft model生成若干个token序列;二是将候选token序列输入到LLM(Target model)中进行验证。因此大部分工作都集中在如何设计和训练一个准确性高同时参数量小的Draft model,以及如何在验证阶段更快的验证那些合理的token序列。一般来说Draft model 要比 Target model 参数量要小很多,每一次迭代至少会生成1个token,最多会生成K+1个Token。speculative decoding取得加速收益的两个关键因素:一是自然语言层面,存在一些比较容易的token可以用更小的代价来生成;二是硬件层面,Batch的情况下硬件不会陷入计算瓶颈。
本文首先会介绍推测解码及其比较经典的EAGLE算法 [1,2],并测试官方开源的权重在A100和S4000上的推理加速结果。接着,我们基于S4000,完成在7B和14B模型在中文数据集上的训练和推理,并报告其推理加速结果。最后是本文的总结。
推测解码与EAGLE算法
推测解码的验证策略
贪婪解码(greedy decoding)
当直接使用贪婪解码来生成,即取概率最大的token时, 只需要直接匹配top-1,遇到不匹配的直接丢弃。如下图,来自Draft model的y2,y3,y4,y5作为input_id输入到大模型中进行验证,最终根据大模型的输出来匹配得到y2,y3,y4这一个序列。

随机解码(Nucleus decoding)
当使用随机解码时,由于选择下一个token是偏随机性的,此时验证的策略则会更复杂一些。下面介绍deepmind的一篇论文[3]中提出的验证算法,他们严格证明了对于任意分布和,通过从和进行投机采样所得到的标记的分布与仅从进行采样所得到的标记的分布是相同的。
算法: 生成并评分初步标记序列(draft tokens)
输入:
- 一个较小的自回归模型(draft model)
- 一个目标大模型(target model)
- 期望生成的标记序列长度 K
输出:
- 最终生成的标记序列
步骤:
1. 生成 draft tokens
a. 使用 draft model 生成一个长度为 K 的初步标记序列(draft tokens)
b. 记录这 K 个草稿标记对应的概率值 p
2. 评分 draft tokens
a. 使用 target model 对这 K 个草稿标记进行评分,获得概率值 q
b. 评分时间与评分单个标记的时间相当
3. 判断是否接受
a. 对于每个草稿标记,计算 min(1, q/p) 作为接受该标记的概率
b. 生成 K 个 [0,1] 范围内的均匀随机数
c. 如果随机数小于等于 min(1, q/p),则接受该草稿标记,否则拒绝
4. 处理接受/拒绝结果
a. 如果所有 K 个草稿标记都被接受,从 target model 直接采样第 K+1 个标记
b. 如果第 t 个草稿标记被拒绝,则:
- 从 q(x) - p(x) >= 0 的修正概率分布中采样一个新标记
- 将之前接受的草稿标记和新采样的标记连接作为最终结果
5. 返回结果
EAGLE算法
动机
-
相比于其他工作如MEDUSA直接预测token,预测“特征”比预测token更简单,特征指的是 LLM 倒数第二层的feature
-
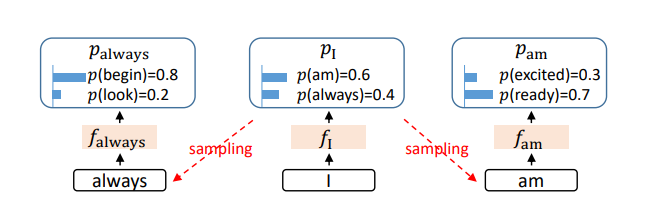
保留特征层可以更好的克服采样过程��中的不确定性。如下图,在输出 I 之后,会按概率采样输出 am 或是 always。在进一步寻找 always 的后续输出时,如果能保留 I 的特征层输出,就能保留住采样过程中丢掉的关于 am 的信息
整体流程
-
产生候选token阶段
在EAGLE算法中,由一个参数量较小的draft model来完成后续token的生成,是比较标准的transformers layer的结构,它的作用是对于输入的最后一层隐藏层的特征和token的embedding特征预测下一个token的隐藏层特征,然后通过原始LM head来预测token在draft model进行预测时。EAGLE draft model是以自回归的形式来迭代预测的,假设它预测了个step,并且我们每个step只保留概率最高的个token,那么我们就可以得到个token序列,这个token序列接下来会一次性送进大模型中进行验证。
-
验证阶段
对于验证阶段得到的条路径序列,如果每条路径都要过一次大模型进行验证,这样代价是很大的。得益于tree attention这种对mask的巧妙设计,我们可以将这条路径组成一棵树的形式并修改对应节点的attention mask,这样就可以大模型前向计算一次就可以完成所有路径的验证[4]。
-
验证阶段的优化
根据上面的介绍,如果我们朴素的将条路径全部进行验证,也可能会有不少冗余的验证计算。因此,在EAGLE-1[1]中,作者经验性的将验证树进行裁剪,只保留m条固定的路径。而在EAGLE-2[2]中,作者利用了Draft model给出的token置信度得分来动态的对草稿树进行裁剪,来选择最有可能的验证序列,从而尽可能实现接受token数量的最大化。
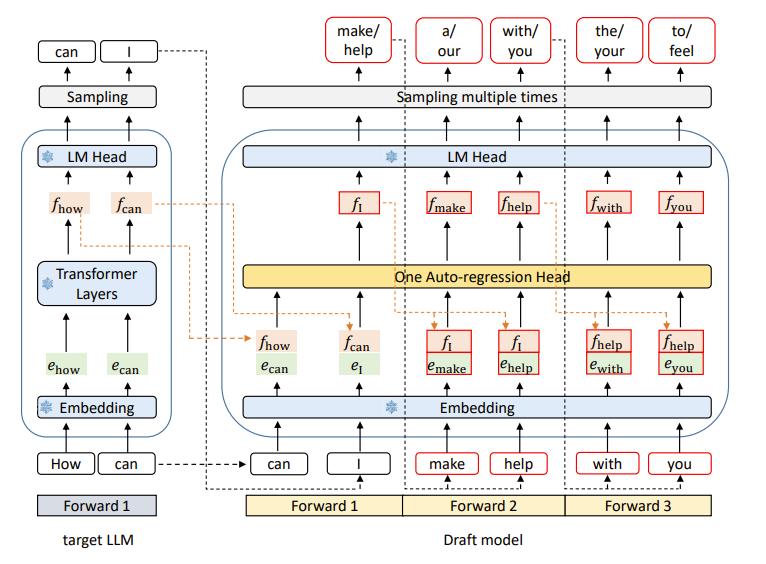
草稿模型(draft model)的训练
在训练draft model时,有两个损失函数一起联合训练,一个是回归损失,即用L1 loss来计算Draft model预测出来的时刻的特征和真实特征之间的差异;另一个是用于增强的分类损失,用交叉熵损失计算时刻最终的预测token与真实token的差异。
作者实验分析表明EAGLE对训练数据的敏感程度很低,因此我们可以用一批提前计算好的数据来并行的训练draft model,从而可以极大的节省训练的代价,类比于训练LLM的next token prediction, 我们可以称训练draft model为next token feature prediction.
EAGLE的加速效果
在本小节中,基于官方训练好的EAGLE-Qwen2-7B-Instruct和EAGLE-Vicuna-13b的权重,我们测试7B和13B模型在A100和S4000上的加速效果。我们选取了英文的alpaca(通用问答)、gsm8k(数学)、humaneval(代码)和sum(文本摘要)四种类型的任务作为测试数据集。其中,一个一般的7B模型对应的EAGLE draft model权重的参数量大约为0.25B,14B模型对应的权重参数量大约为0.38B。(注:官方放出的权重中未在中文训练集上训练,同时本博客的实验均是使用贪婪解码策略下的加速结果。)
7B模型的EAGLE推理加速结果
| alpaca | gsm8k | humaneval | sum | |
|---|---|---|---|---|
| A100 | 2.92x | 3.0x | 3.09x | 2.91x |
| S4000 | 1.90x | 1.94x | 1.98x | 1.76x |
14B模型的EAGLE推理加速结果
| alpaca | gsm8k | humaneval | sum | |
|---|---|---|---|---|
| A100 | 3.03x | 3.14x | 3.50x | 2.47x |
| S4000 | 2.23x | 2.30x | 2.46x | 2.10x |
EAGLE on S4000
在本节中,我们基于S4000完成在qwen2-7B-instruct和 Qwen2.5-14B-instruct模型在中文数据集上的EAGLE draft model的分布式训练,并测试其在中文测试集上的加速效果。
训练
首先,我们利用了开源的Magpie-Qwen2-Pro-200K-Chinese和Sharegpt_zh数据集,从中抽取了约70k条数据作为训练集,利用官方仓库[5]中的ge_data_all_qwen2.py文件来提前生成好训练数据。 其次,我们基于kuae1.3环境做分布式训练,我们既可以使用acclerate(accelerate>=0.33已经支持了musa后端)来训练,也可以使用适配好的deepspeed来训练。如果使用deepspeed,我们只需要在官方仓库中的main_deepspeed.py的启动脚本中加入以下几行musa的环境变量,即可启动musa的单机多卡训练。
export MUSA_VISIBLE_DEVICES='0,1,2,3,4,5,6,7'
export DS_ACCELERATOR=musa
export MCCL_PROTOS=2
export MUSA_KERNEL_TIMEOUT=18000000
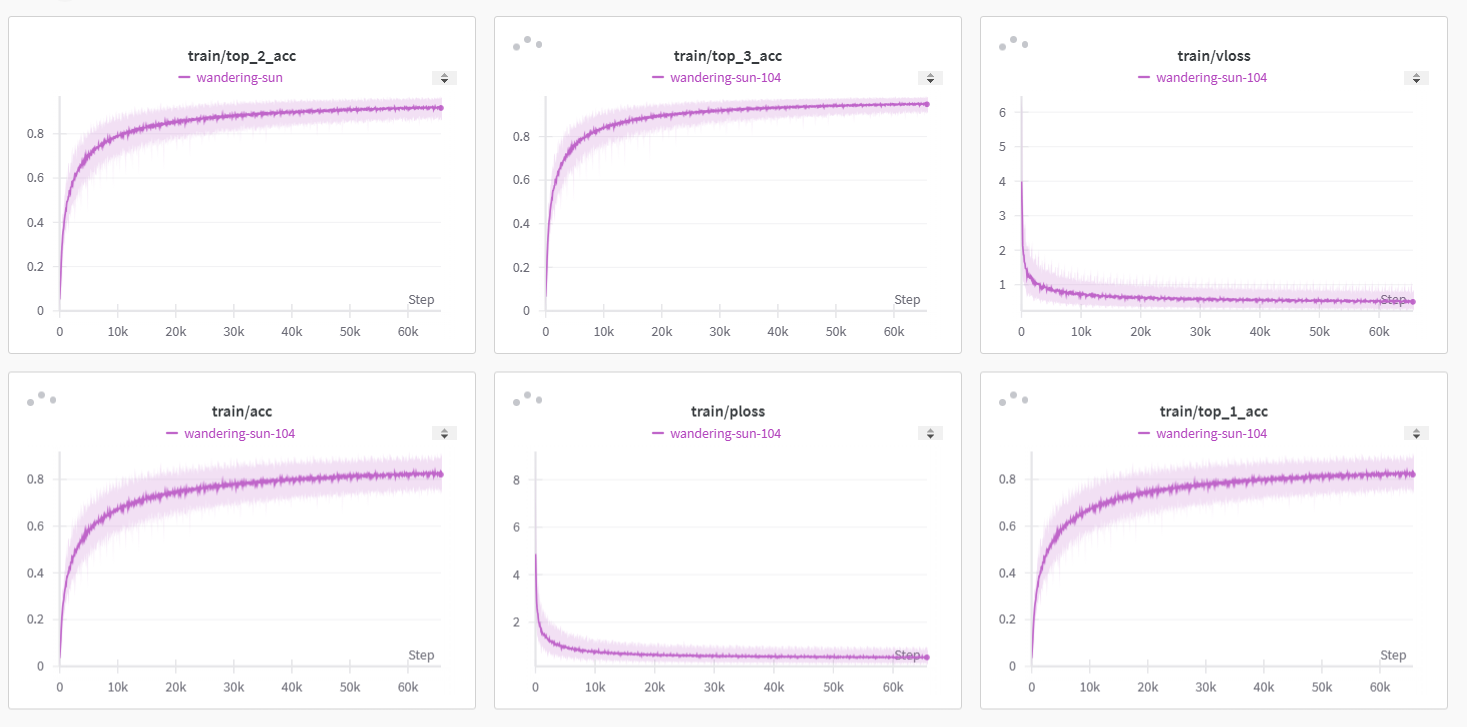
最终,我们可以得到如下的14b模型的eagle模型训练曲线图,top-3 acc约0.95,top-1 acc约为0.84。
推理
我们使用了两类任务来评测EAGLE在S4000上的推理加速结果,一类是alpaca,即从开源的alpaca通用问答数据集收集了50条prompt;另一类是writing,开源的创意写作数据集中抽取了50条prompt,其特点是生成的文字都比较长。
7B模型的EAGLE推理加速结果
| alpaca | writing | |
|---|---|---|
| A100 | 2.73x | 2.55x |
| S4000 | 1.75x | 1.94x |
14B模型的EAGLE推理加速结果
| alpaca | writing | |
|---|---|---|
| A100 | 2.92x | 2.79x |
| S4000 | 2.00x | 1.90x |
最后,我们可以简单分析一下影响EAGLE算法加速效果的两点主要原因。
- Draft Model预测的准确率。一般而言由于中文的token粒度要大于英文token的粒度,因此在中文上预测下一个token的难度要大一些,准备率可能会低一些。在本实验中我们发现,14B模型的EAGLE的中文平均接受token长度约为3.1,而论文中平均约达到了3.8以上,因此,本实验所训练的EAGLE模型,应该说也还有较大的优化和提升空间。
- batch情况下的计算耗时。在推理时,我们利用EAGLE模型会得到很多条序列路径,并根据得分选择最终的K条路径,以batch的形式给大模型前向计算做验证,选择最终可接受的token序列。在这个过程中,如果K=1与K=m(m>1)情况下,大模型前向计算一次的耗时是大致相近的,那么此时获得的理论收益是可观的;否则,如果随着K增大,大模型的耗时会按照某种比例增加,那么此时获得的收益也会递减。总的来说,具体的收益取决于不同GPU的算力,带宽及其软件栈的实现和优化方式。
总结
在这篇博客中,我们介绍了传统的自回归解码和推测解码算法EAGLE,其中推测解码的加速主要来源于一些比较容易的token可以用更小的代价来生成以及Batch的情况下GPU不会陷入计算瓶颈,本质上是一种利用冗余算力换取速度的方法。基于S4000,我们完成了中文上的7B和14B模型的EAGLE模型的训练与推理,并且分别取��得了平均约1.80x和1.95x的加速收益。可以看到,基于S4000或者MT-GPU,已经可以很方便的完成大模型的训练和推理实验。
当然,推测解码也不无缺点,它需要额外训练一个草稿模型,不像flash attention拿来即用,同时推测解码这种用算力换时间的方式,可能会影响推理系统的吞吐量。因此,在像VLLM等推理加速框架比较成熟的情况下,将推测解码算法与像VLLM这种加速框架结合来进一步提升系统吞吐量可能是另一个值得研究的问题,此时需要考虑系统吞吐量和系统延迟之间的权衡。不过,随着近期openai O1,以及deepseek-R1等具有超长思维链过程的擅长逻辑推理的大模型的兴起,给大模型的inference带来了新的挑战,也给推测解码这类技术带来新的机遇。
参考文献
- Li, Yuhui, et al. "Eagle: Speculative sampling requires rethinking feature uncertainty." arXiv preprint arXiv:2401.15077 (2024).↩
- Li, Yuhui, et al. "Eagle-2: Faster inference of language models with dynamic draft trees." arXiv preprint arXiv:2406.16858 (2024).↩
- Chen, Charlie, et al. "Accelerating large language model decoding with speculative sampling." arXiv preprint arXiv:2302.01318 (2023).↩
- Cai, Tianle, et al. "Medusa: Simple framework for accelerating llm generation with multiple decoding heads." 2023,(2023).↩
- https://github.com/SafeAILab/EAGLE.↩

