在摩尔线程 MTT S80 上使用 Ollama 进行 DeepSeek R1 蒸馏版模型推理
什么是 Ollama?
Ollama 是一个工具和平台,专注于简化和优化大语言模型( LLM )的管理和部署。它主要提供了一种方便的方式,在本地或边缘设备上运行、管理和调用大型语言模型,同时通过其特有的 Docker 集成和 API 接口,使得 LLM 的使用更加灵活、轻量且安全。
Ollama 因为其本地化、轻量级和灵活性,成为一种在多个环境中管理和部署 LLM 的理想工具。
使用 Ollama 进行 Deepseek R1 蒸馏版模型推理
以下代码运行在 x86 架构的 Ubuntu 20.04/22.04 系统。
配置容器运行时
请参考以下链接安装和配置容器运行时。
- 安装 Docker: Docker 安装指南。
- 安装 MTT S80 最新驱动 (当前最新版本为 rc3.1.1): MUSA SDK 下载。 注意该版驱动类型为 compute-only,可能存在图形界面无法启动的风险。
- 安装 MT Container Toolkit (当前为 v1.9.0): MT CloudNative Toolkits 下载
检查容器运行时配置是否正确,确认输出的默认运行时为 mthreads。
$ (cd /usr/bin/musa && sudo ./docker setup $PWD)
$ docker info | grep mthreads
Runtimes: mthreads mthreads-experimental runc
Default Runtime: mthreads
拉取镜像并运行容器
拉取 Ollama 镜像:
docker pull mthreads/ollama
启动容器:
docker run -it -d --name=ollama -v {your_host_dir}:/root/.ollama mthreads/ollama
以上命令:
- 启动并运行一个基于
mthreads/ollama镜像的容器。 -it:交互式运行容器,分配一个伪终端。-d: 将容器运行在后台。--name=ollama: 将容器名指定为“ollama”。-v {your_host_dir}:/root/.ollama: 将主机的{your_host_dir}目录挂载到容器内的/root/.ollama目录。因为/root/.ollama是镜像默认使��用的ollama数据存放目录,挂载该目录后即使容器被销毁,下载的模型数据文件依然会被保存在指定的{your_host_dir}目录下。{your_host_dir}可根据用户实际情况填入。
进入容器:
docker exec -it ollama bash
运行模型:
ollama run deepseek-r1:7b --verbose
等待 Ollama 模型拉取完成后,即可以开始对话。 加入--verbose参数以显示模型性能,可根据需要选择是否传入。
监测 GPU 状态
在与模型对话的同时,可以通过另外启动一个终端并执行:
watch -n 1 mthreads-gmi
来实时观测 GPU 的利用率等状态数据。以上-n 1代表每一秒刷新一次,实际可根据需要调整设置。
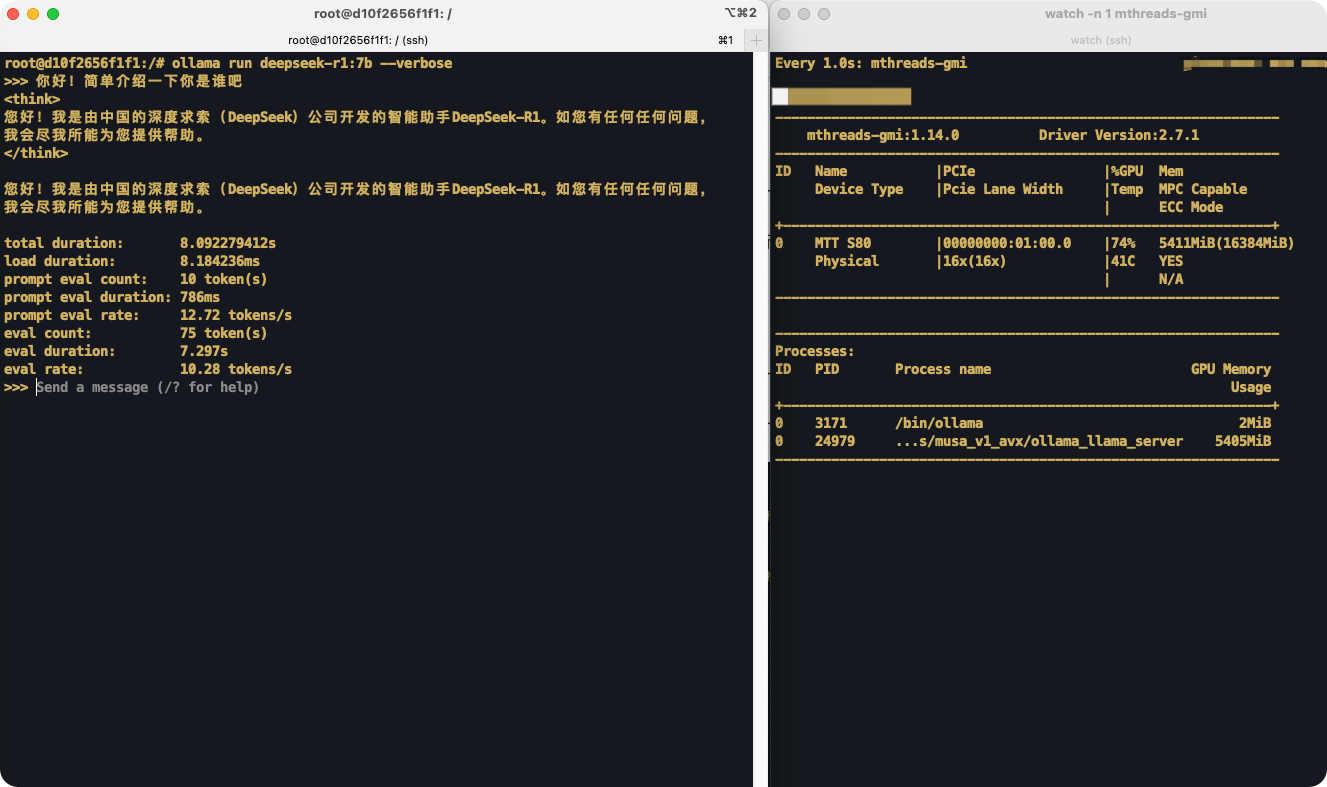
以下是��运行deepseek-r1:7b的示例图:
以下是运行deepseek-r1:14b的示例图:
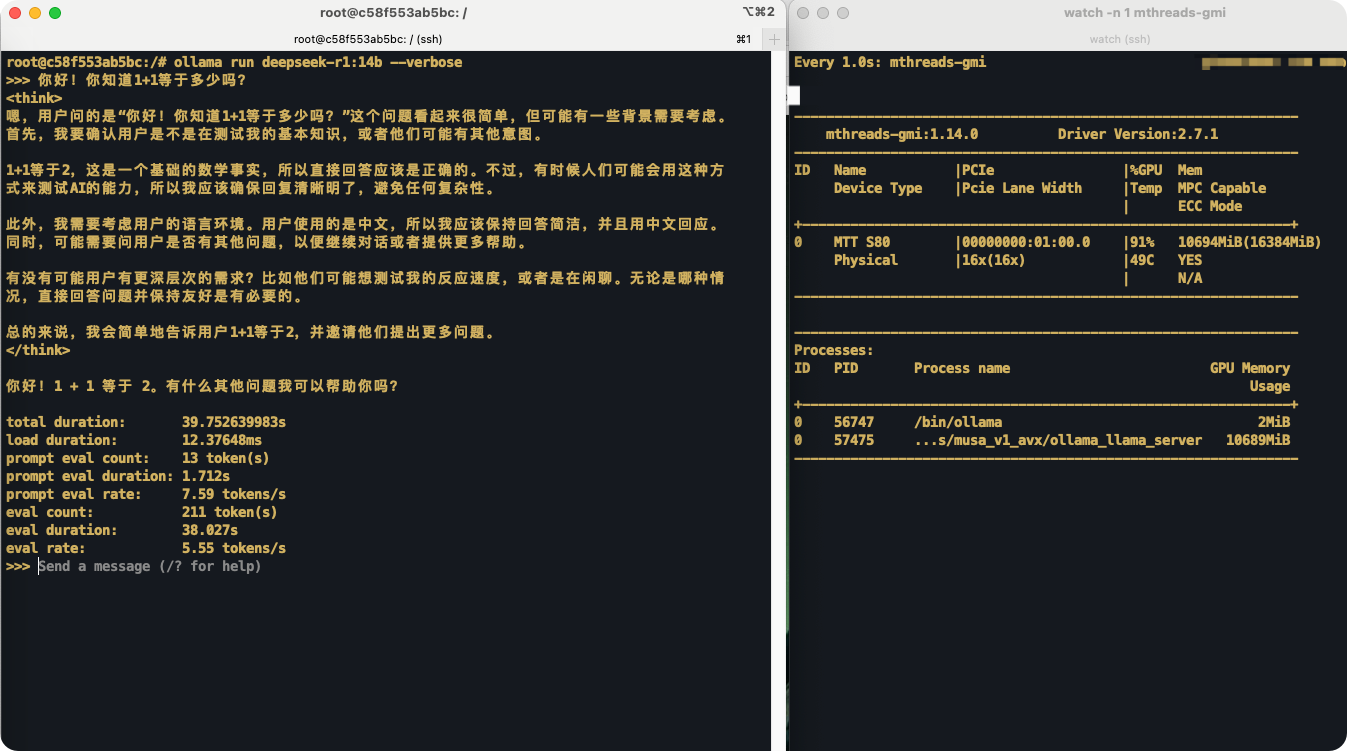
完整的R1蒸馏模型列表可以在 Ollama 官网找到。以 MTT S80 为例,其可以运行包括 deepseek-r1 1.5B/7B/8B/14B 的模型。
Open WebUI界面
也可以结合 Open WebUI 来创建一个通用的用户界面,实现类似OpenAI的聊天界面。配置详情参考使用摩尔线程 GPU 搭建个人 RAG 推理服务。

